C++ Multithreading (Part 3)[1]
C++ Memory Model
Atomics, 넌 누구냐
thread 헤더에 관련된 레퍼런스를 여행하다 보면 심심찮게 등장하는 변수들이 있는데 std::atomic_xxx 시리즈들입니다. 이전에 std::lock_guard 등의 객체를 선언하여 여러 쓰레드가 접근하지 못하도록 mutex를 처리했다면, std::atomic 변수들은 기본적으로 원자적 연산을 지원하는 변수들입니다.

여기서 원자적 연산(atomic operation)이란 언어 그대로 해석하면 편합니다. 원자는 물질을 구성하는 요소로 더 이상 쪼개지지 않습니다. 즉, 어떠한 연산을 구현할 때 한 변수에 관련된 연산의 쪼개짐(여러 단계로 나누어 연산되는 것)에 대한 방지를 보장하는 것이 원자적 연산이라고 할 수 있습니다.
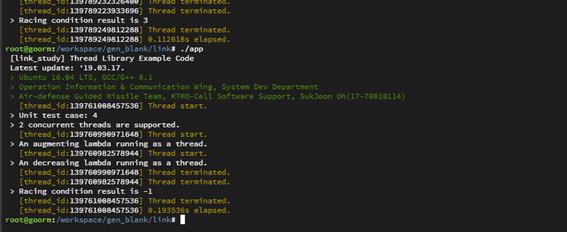
그렇다면 어떠한 연산이 쪼개질 수 있는가에 대한 물음이 남습니다. 단적으로 Part 1에서 이용했던 예시를 가져와보겠습니다.
int counter = 0;
std::thread worker_thread_1([&]() {
APP_THREAD_START
std::cout << " > An augmenting lambda running as a thread." << std::endl;
for(int itor = 0; itor < 100; itor++) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
}
APP_THREAD_TERMINATE
});
std::thread worker_thread_2([&]() {
APP_THREAD_START
std::cout << " > An decreasing lambda running as a thread." << std::endl;
for(int itor = 0; itor < 100; itor++) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter--;
}
APP_THREAD_TERMINATE
});
if(worker_thread_1.joinable())
worker_thread_1.join();
if(worker_thread_2.joinable())
worker_thread_2.join();
std::cout << " > Racing condition result is " << counter << std::endl;
하나는 counter 변수를 증가시키는 놈이고 counter 변수를 감소시키는 놈이었습니다. 동일한 횟수로 증가/감소 시키고 있으니 분명히 우리가 기대하는 값은 0이어야 맞을 텐데 결과는 그렇지 않았습니다. 프로그램을 실행시킬 때마다 한번은 3, 한번은 -1을 출력하고 있었습니다.
코드는 아주 단순합니다. 연산에 대한 부분은 171번과 185번 줄 입니다.
counter++;
counter--;
그렇다면 왜 이런 경우가 발생하느냐? 컴파일러는 우리가 작성한 코드 곧이곧대로 변환해주지 않습니다. 프로그래머보다 컴파일러가 똑똑하기 때문입니다. 컴파일러는 자체적으로 최적의 성능(performance)을 내도록 코드를 재작성합니다. 이를 최적화라고 합니다. 즉, 내가 작성한 171번과 185번 줄이 내가 의도했던 한 줄이 아니라 여러 단계에 나누어 기계어로 번역되었을 가능성이 큽니다.
자료를 찾다보면 원자적 연산에 대한 명확한 정의를 찾기 힘들거나 매우 추상적이어서 이해하기 어려운 경우가 많습니다. 일단은 여기서는 이렇게 이해하고 넘어가도록 합시다.
그렇다면 돌아와서, 원자적 연산을 지원하는 변수들이 왜 심심찮게 쓰레드와 같이 등장하는지 알 수 있습니다. 공유 변수에 대한 읽기와 쓰기가 다수의 쓰레드에서 진행될 때 Part 1에서는 std::mutex 객체를 이용하여 직접 울타리(Fence)를 지정했다면, 이제는 추가적으로 그럴 필요 없이 자동으로 std::atomic 변수에 대한 연산은 원자성이 보장되도록 하겠다는 겁니다. 레퍼런스에도
“Atomic objects are free of data races.”
라고 명시되어 있는 것을 확인할 수 있습니다.
Atomics와 Memory Model의 관계
그러면 std::atomic 레퍼런스를 뒤져봅시다.
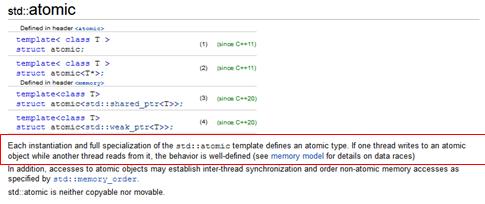
“If one thread writes to an atomic object while another thread reads from it, the behavior is well-defined(see memory model for details on data races) “
라고 합니다. 한 쓰레드가 원자적 객체를 읽을 때 다른 놈이 쓰고 있는 경우 그에 대한 동작은 아주 잘 정의된다고 합니다.
아주 잘 정의된답니다. 자세한건 메모리 모델(memory model)을 보랍니다. 들어가 보면 뭐라뭐라 써져 있고, 그 중에 한 놈이 눈에 띕니다.

그렇군요. 그러면 std::memory_order를 찾아봅시다.
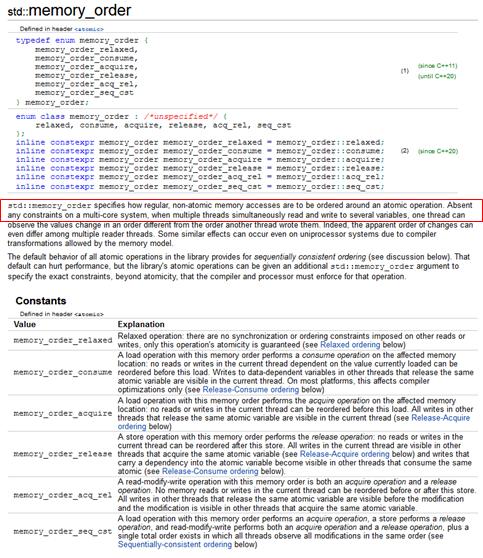
붉은 색으로 표시한 부분을 간단하게 해석하면 원자적 변수가 아닌 놈에 대한 메모리 접근을 어떻게 정렬(order)하는지 결정하는 옵션이라고 합니다.
음… 뭐라는 겁니까…? 그 밑에 relaxed, acquire, release… 설명을 읽어도 쉽게 와 닿지 않습니다.
C++ Memory Model에 관련한 자료를 찾아보면 한글로 되어 있는 자료는 많지 않습니다. 더군다나 영어로 되어 있어도 알아듣기 쉽게 설명되어 있는 친절한 자료는 찾기가 힘듭니다.
그나마 찾은 게 Martin Kempf(mkempf@hsr.ch)의 “C++ Memory Model”이라는 자료가 조금 쉽게 접근할 수 있는 내용을 담고 있습니다. 이 자료를 보면서 C++ Memory Model에 대한 아이디어를 잡아봅시다.
해석과 동시에 자료에 대한 기술적 이해를 하는 것은 늘 까다롭습니다. 해석/이해에 대한 오류가 있을 수 있으니 참고 바랍니다.
원문의 일부와 개인적인 이해/해석이 동시에 기술되어 있습니다. 참고 바랍니다.
중요하다고 판단된 내용만 원문을 인용해 작성하였습니다. 원문과의 내용이 1대 1로 일치하지는 않습니다.
필자는 공군 작전정보통신단 체계개발실에서 복무(‘17~’19)하였습니다. 이 포스트는 작전정보통신단 병사 프로그래밍 동아리(LINK) 에서의 활동을 바탕으로 작성한 내용입니다.