C++ Multithreading (Part 3)[2]
Abstract
Prior to C++11, multi-threading in C++ was supported only by libraries and the language was specified as a single threaded language. With the memory model introduced in C++11 threading support is integrated into the language specification and therefore exactly defines the behavior of multi-threaded applications.
Further more, the simple usage of atomic operations is introduced to allow the implementation of lock-free algorithms and therefore a more performance conscious way of programming.
서론입니다. 중요하지 않은 내용은 날려버립시다. 뭐, 그래도 대부분 아는 내용입니다. C++11로 오기 이전에는 쓰레드 구현은 라이브러리로만 가능했고 이는 C++11이전에는 언어적으로 싱글 쓰레드(single threaded)를 지원했다는 점, 새로운 메모리 모델(memory model)과 함께 정확한 다중 쓰레드의 행동(behavior)이 정의되었다는 내용입니다. 또한 Part 1에서 설명했던 lock을 사용하지 않은 원자적 연산 프로그래밍을 지원한다는 내용입니다.
이 자료(paper)에서는 왜 메모리 모델(memory model)이 등장했는지에 대해 설명하고 있습니다. 순서는 아래와 같습니다.
The model is first explained with all ①atomic operations to execute sequentially consistent, followed by the ②enhanced model with atomic operations to relax the sequential consistency guarantee.
②의 ‘relax’의 의미는 뒤에 가 보면 알겠지만 sequential consistency를 조금 더 유연하게 적용하겠다는 의미입니다.
지금부터 새로운 용어가 나올 텐데 굵은 글씨로 통일하겠습니다.
1. Introduction
Direct hardware support for shared-memory is a performance advantage.
아주 단순하게 생각해보면 왜 병렬 프로그래밍(parallel programming)이 인기가 많은지는 알 수 있습니다. 성능상의 이점(performance advantage)이 있기 때문일 것입니다. 여기서 shared-memory에서 중요한 요소를 메모리 모델(memory model or memory consistency model)이라고 설명합니다.
An important part in shared-memory parallelism is the memory model or memory consistency model.
The language was specified as single-threaded language. The execution of multi-threaded applications, programmed with a single-threaded-defined language and a library for threading support, was based on an agreement between compiler and hardware. This also affected the portability. With the new C++11 standard, threading support is a part of the language specification and a memory model is defined. This gives a guaranteed behavior in multi-threaded programs and better portability.
두 가지만 보면 됩니다. C++11 이전에서 라이브러리로 구현했던 방식은 컴파일러와 하드웨어 간의 모종의 규약(agreement)에 의존했습니다. 이건 당연히 이식성(portablity)에 영향을 줄 수밖에 없었을 겁니다. C++11 스펙에 메모리 모델이 새로 정의되면서 다중 쓰레드 프로그램에 대한 행동(behavior)이 보장되었고 이식성도 좋아졌습니다.
1.1. What is a Memory Model
여기서는 간단한 예를 들면서 왜 메모리 모델(memory model)이 필요한지 감을 잡아봅시다.
When multiple threads can access the same memory location in parallel, it must be specified which set of values a read can return. A memory model species concurrency semantics in shared-memory programs.
다수의 쓰레드가 하나의 메모리 위치에 병렬로 접근할 때 어떤 값(which set of values)이 읽는 과정(a read)에서 리턴 되어야 할지가 중요합니다. 예를 들어 봅시다.

Figure 1: Load and store of a shared variable x, performed by different threads on cores that do not share the cache.
Thread 1은 core A에서 동작하고 어떤 위치(memory location)에 값을 쓰고 있고, Thread 2는 core B에서 동작하며 그 후에 동일한 위치의 값을 읽어 들이고 있습니다. 여기서 드는 의문은, 과연 어느 값이 읽힐 것이냐는 겁니다. core가 cache를 공유하고 있지 않는데도 정확히 Thread 1이 저장한 값을 읽을 수 있을까요?
The question is, whether there is enough synchronization to ensure that a thread’s write will occur before another’s read.
The compiler as well as the processor can reorder instructions in order to increase the performance. These reordering can also unintentionally influence the behavior of a program, especially in multi-threaded programs (see example in Section 1.2).
결론적으로는 결과는 보장되지 않습니다. 컴파일러와 프로세서는 성능 향상을 위해 명령(instructions)을 재정렬(reorder)할 수 있습니다. 때문에 의도치 않게 프로그램의 행동을 망가뜨릴 수 있습니다.
여기서 reorder을 재정렬이라 표현하겠습니다.
메모리 모델은 이러한 상황에서 일종의 프로그램과 하드웨어(또는 소프트웨어)사이의 일종의 규약이라고 이해하면 편합니다. 컴파일러와 하드웨어가 멋대로 명령을 재정렬하는 현상을 의도적으로 제한하고, 때문에 유용성(usability)과 성능(performance)이 줄다리기 하는 상황이 벌어집니다.
더 자세한 예는 1.2에서 봅시다.
1.2 Sequential Consistency
sequential consistency를 직역하면 ‘연속적인 일관성’ 정도 일 텐데, 역시 억지로 번역하면 받아들이는 의미가 조금 퇴색하는 듯 합니다. 여기서부터는 소개되는 용어의 직역은 최대한 피하도록 하겠습니다.
sequential consistency는 Lamport가 처음 가지고 온 아이디어인데, 가장 직관적(the most intuitive one)입니다. 이는 아래와 같습니다.
Hardware is sequentially consistent if the result of any execution is the same as if ①the operations of all the processors were executed in some sequential order, and ②the operations of each individual processor appear in this sequence in the order specified by its program.
한마디로 하드웨어가 sequentially consistent 하기 위해서는 모든 실행(execution)의 결과가 동일해야 하며, 이는 마치 모든 프로세서의 실행이 어떤 연속적인 순서로 진행되어야 한다는 겁니다.
이 개념을 다른 예시에 적용해 봅시다. 일단은 원문에서는
Additionally we interpret the term operation as memory operation and the term result as the set of values read and the final value of the execution.
연산(operation)은 메모리에 대한 연산으로, 결과(result)는 읽힌 값 또는 실행 후의 마지막 값(values read and final value of the execution)으로 해석합니다.
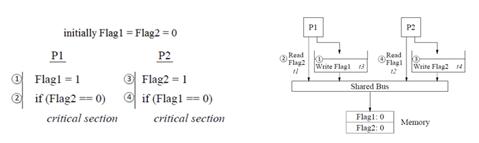
Figure 2: For sequential consistency, all memory accesses appear to execute atomically in some total order and program order is maintained among operations of each processor.
Figure 3: Store buffer violates sequential consistency. t1, t2… indicate the order in which the corresponding memory operations execute at memory.
임의의 연속적인 순서(some sequential order)라면 가능한 연산 순서의 조합(possible combinations of the instruction)은 그림과 같이 1번부터 4번일 수 있습니다. 그리고 추가적으로 각각의 다른 조합에서는 읽는 연산(read operation)은 직전에 각 변수에 쓰여진 값을 읽습니다. 만약 연산(memory operation)이 원자적으로 실행되도록 강제된다면 Flag1과 Flag2가 모두 0이 될 수는 없습니다. 이건 당연합니다.
그런데, 대부분의 현대 프로세서(modern processor)들은 저장에 대한 지연을 막기 위해 항상 버퍼를 이용합니다. 이러한 경우는 Figure 3를 보면 알 수 있습니다.
Each processor can buffer its write and allow the subsequent read to bypass it.
그림을 보면 직관적입니다. 쓰기 연산을 수행하기 위해 버퍼에 값을 채우고, 값이 실제로 쓰이기 전에 읽어버립니다. 따라서 정상적이라면 0이 될 수 없는 Flag1과 Flag2 변수가 읽는 연산에 의해 모두 결과 값이 0이 되어버리는 현상이 발생합니다. 이러한 경우 sequential consistency를 위반하게 됩니다.
1.3 Software- and Hardware Memory Model
위와 같은 단적인 예로 하드웨어와 소프트웨어 모두 메모리 모델에 적용되어야 합니다. 만약 하드웨어 모델이 느슨하다면(약하다면, weaker) Figure 3와 같은 경우를 허용합니다.
The solution to this problem is to let the compiler add memory fences that prevent the hardware from performing violating reordering.
물론, 메모리 울타리(?)(memory fence)를 이용하여 재정렬을 방지할 수는 있습니다. 다만, 위와 같이 완전히 막아버리는 경우(full fence) 고작 두 개의 쓰레드의 동기화에서 너무 많은 비용을 지불합니다. 소프트웨어의 모델을 하드웨어 모델로 이용하는 건 성능상의 문제가 발생할 수 있습니다.
직역의 한계가 있을 수 있습니다.
2. Motivation for C++ Memory Model
C++에서는 병렬성(또는 동시성, concurrency support)에 대한 지원을 외부 라이브러리가 지원하도록 했습니다. 대표적으로 Pthread 라이브러리가 있습니다. 대부분의 경우 C++ 병렬 프로그래밍에서는 외부 라이브러리로 작성해도 괜찮습니다. 그런데 간혹 라이브러리에 의한 접근이 실패할 경우가 있습니다. Section 2에서는 정형화된 메모리 모델(formalized memory model)이 언어 스펙(language specification)에 들어갔어야 하는 이유가 뭔지 간단히 봅시다.
2.1. The Library Approach with Pthread
PThread 라이브러리를 이용해야 하는 경우 아래의 규칙을 따라야 합니다.
Applications shall ensure that access to any memory location by more than one thread of control (threads or processes) is restricted such that no thread of control can read or modify a memory location while another thread of control may be modifying it. Such access is restricted using functions that synchronize thread execution and also synchronize memory with respect to other threads…
대충 요약하자면 어느 한 쓰레드가 한 메모리 위치를 수정(modify)하는 중이라면 다른 쓰레드는 그 위치를 읽거나 쓰면 안된다 라는 겁니다. 그 제약을 위한 함수가 대표적으로 pthread_mutex_lock과 pthread_mutex_unlock인데, 이 함수를 이용할 때에도 위의 규칙을 준수해야 됩니다. 함수 적용은 아래와 같습니다.
- The implementation of the synchronization functions such as pthread_mutex_lock must guarantee that the memory is synchronized. This is realized by adding memory fences that are specific to the underlying hardware. The fences therefore preclude a hardware reordering of memory operations around calls to synchronization operations of Pthread. This is shown in Figure 4.
- Also the compiler must prevent the reordering as seen in Figure 4. The compiler therefore treats calls to functions such as pthread_mutex_lock as calls to opaque functions. This means the compiler has no information about the function and assumes in this function read and write operations on any global variable. This assumption prevents the compiler to simply move the memory operation around the calls.
1번은 메모리가 동기화(synchronized) 되도록 보장해야 된다는 내용입니다. 울타리(fence)를 설치할 때 하드웨어 적으로도 재정렬(reordering)이 일어나면 안 됩니다. 2번은 컴파일러 단에서도 재정렬이 일어나면 안 된다는 이야기입니다. 컴파일러는 함수에 대한 정보가 전혀 없다는 겁니다. 이를 그림으로 나타내면 Figure 4가 됩니다.

Figure 4: Implementation of Pthread must prevent the reordering of memory operations around synchronization operations as pthread_mutex_lock and pthread_mutex_unlock.
당연한 이야기입니다. lock 사이에 변수의 수정이 일어나야지 그 외의 범위에서는 결과가 보장되지 않을 테니까요. 위의 규칙과 적용법까지 고려하면 다음과 같이 정리할 수 있을 것입니다.
-
The semantic of programs with races is undefined. (While the definition of a race is not made in Pthread. See Section 2.2.1)
-
Synchronization-free code can be optimized as though it were single-threaded.
-
It is easy to write wrong code for example by an incorrect ordering of pthread_mutex_lock and pthread_mutex_unlock.
특별한 것은 없습니다. Data race는 정의되지 않으며, 동기화가 없는 코드는 단일 쓰레드인 것처럼 고려되어 최적화되고, lock과 unlock의 순서를 제대로 작성하지 않아 잘못된 코드를 작성할 수 있다는 것 정도입니다. 이 부분에서는 Pthread 라이브러리에 대한 내용이 주가 아니기 때문에 그러려니 하고 넘어갑시다.
2.2. Possible Implications of the Library Approach
2.2.에서는 Pthread 라이브러리를 사용한 병렬 프로그래밍이 실패하는 경우를 세 가지에 걸쳐 소개합니다. 그 중 하나는 메모리 모델이 왜 언어 스펙에서 정의가 되어야 하는지에 대한 이유를 설명하므로 자세히 다루고, 나머지는 간단히 짚고 넘어갑시다.
2.2.1. Concurrent Modification
위의 Pthread 라이브러리 규칙에 의하면 “no thread of control can read or modify a memory location while another thread of control may be modifying it.”가 있습니다. 그러면 우리는 Concurrent Modification(또는 data race)가 언제 일어나는지 알아야 동기화 연산(synchronization operations)를 적용하는지 결정할 수 있을 것입니다. 아래의 예시를 봅시다.

Figure 5: Is there a concurrent modication? Do we need synchonization operations?
Figure 6: Possible reordering of code in Figure 5 by the compiler imposed by speculative execution
sequentially consistent execution 상태라면 data race는 일어나지 않습니다. 따라서 비교문의 x==1 과 y==1은 절대 참이 될 수 없습니다. 두 변수 모두 0이 아닌 수로 변경될 수 없기 때문입니다. 그렇지만 아래의 문장이 중요합니다.
But according to the Pthread approach, a compiler may freely reorder memory operations that are free of synchronization operations.
Pthread approach 섹션에서 “Synchronization-free code can be optimized as though it were single-threaded.”로 정리 가능하다 했습니다. 즉, 동기화에 대한 정보가 없는 코드이기 때문에 최적화 과정에서 Figure 6와 같이 코드를 바꾸는 경우가 생깁니다.
sequentially consistent인 상태이기 때문에 비교문의 x==1 과 y==1은 참이 될 수 있는 상태로 바뀝니다. 따라서 Pthread approach에 의한 접근은 언어적 정의(unaware language definition)를 따르지 않는 변환에 의해 data race가 발생할 수 있습니다. 이 문제는 언어적으로 정의되며(programming-language-defined) 컴파일러 측을 고려한 메모리 모델을 정립함으로써 프로그래머와 컴파일러 사이의 data race 방지를 보장할 수 있다는 내용입니다.
2.2.2. Memory Location and Register Promotion
위의 이유 말고도 추가적으로 두 가지가 더 있는데 간단하게 이야기 하자면 모두 컴파일러가 생성하는 thread-unaware한 코드 변환(transformation)에 의한 것입니다. 우선적으로, ①메모리 위치(memory location)의 명확한 정의가 필요합니다. 정의가 정립되면 컴파일러가 암묵적으로 서로 인접한 메모리 위치에 쓰는 것을 막는 최적화 규칙이 정립될 수 있습니다.
Register promotion 또한 비슷합니다. 자주 쓰이는 값들은 메모리에서 레지스터로 불러(reload)오는 짓을 여러 번 하는 것 보다 ②레지스터위에 살아 있도록 유지하는 것이 더 좋을 겁니다. 레지스터가 값을 유지(keop)하는 것이 불가능하다면 메모리로부터 여러 번 값을 읽어와야 하고, 그러면 lock 밖의 범위의 입출력(read and writes outside of locks)으로 인해 행동이 정의되지 않을 겁니다.(Figure 3의 내용입니다)
2.3. Conclusion
Pthread와 같은 외부 라이브러리에 의한 다중 쓰레드의 구현은 대부분의 상황에서 정상적으로 동작합니다. 그러나 간혹 위에서 훑어 본 몇 가지의 경우에서 문제가 발생하고, 근본적으로 컴파일러와 구현 하드웨어(target hardware)에 크게 의존하는 것을 알 수 있습니다.
This approach cannot guarantee continued correctness and portability of the application as the compiler evolves and more aggressive optimizations are added, or as the application is moved to a different compiler.
그리고 이러한 접근은 컴파일러가 진화하면서 더욱 더 공격적인 최적화(optimization)을 제공할수록, 어플리케이션이 다른 종류의 컴파일러로 작성되어 질수록 정확성과 이식성을 보장할 수 없습니다. 추가적으로 lock과 unlock을 반복할수록 성능상의 문제가 존재합니다.
필자는 공군 작전정보통신단 체계개발실에서 복무(‘17~’19)하였습니다. 이 포스트는 작전정보통신단 병사 프로그래밍 동아리(LINK) 에서의 활동을 바탕으로 작성한 내용입니다.