C++ Multithreading (Part 3)[3]
C++ Memory Model
3. The C++ Memory Model
표준화된 메모리 모델(memory model)은 data race가 존재하지 않는(data race free) 모델입니다. 즉, data race가 어떤 행동을 할지 정의 자체가 되어있지 않다는 말입니다.
C++는 atomics를 통해 단순화된 원자적 연산(atomic operation)을 제공합니다. atomics는 여러 개의 정렬 옵션(ordering option)을 먹일 수가 있는데, 이는 앞서 보았던 레퍼런스에서 아래에 해당하는 내용입니다.

예를 들어 atomics를 sequential consistent execution 옵션을 준다면 sequential consistent model로 동작합니다. 그 외로 성능 상의 이점을 위해 더 유연한(relaxed) 모델들을 제공하고 있습니다. 조금 더 유연한 모델을 로우 레벨(low-level) atomics라고 합니다. 이번 장부터는 sequential consistent 모델과 유연한(relaxed) 모델인 로우 레벨(low-level) 모델에 대해 감을 잡아봅시다.
3.1. Model Overview
아래의 Figure 7은 C++에서 가능한 정렬 모델(ordering model)과 그에 따른 옵션(ordering options)들을 나타내고 있습니다.

Figure 7: Possible ordering models in C++ with the ordering options that lead to the used model.
여기서 알아 두어야 할 것은 각각의 메모리 모델은 CPU 아키텍쳐마다 각기 다른 비용(varying costs)을 요구합니다. 예를 들어 어떠한 특정한 아키텍쳐에서는 sequential consistent ordering에서 acquire-release ordering 보다 추가적인 동기화(synchronization)을 요구할 수 있습니다. 추가적인 동기화에 대한 영향은 프로세서가 많은 시스템일수록 클 겁니다.
3.2. Basics
이 장에서는C++ 메모리 모델에 대한 기본적인 내용을 설명하고 있습니다.
3.3. Objects and Memory Location
A memory model comprises two aspects. The structural and the concurrency aspect. The structural aspect is about how objects and values are organized in memory. It is the basic to dene whether there is potential of a concurrent access.
메모리 모델(memory model)은 두 가지 측면(aspect)로 볼 수 있습니다. 하나는 구조적(the structural) 측면이고 하나는 동시성(the concurrency) 측면입니다. 프로그램이 실행될 때 메모리 연산(memory operation)은 어떤 특정한 메모리 위치(memory location)에 접근(access)합니다. 아래 Figure 8은 흔히 아는 구조체의 메모리 구조를 나타냅니다.
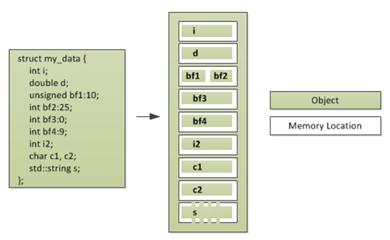
Figure 8: The division of a struct into objects and memory locations.
단순한 내용이라도 다시 한 번 짚고 넘어갑시다. 비트 필드(bit fields) 변수 bf1과 bf2는 크기가 각각 10bit, 25bit입니다. 하나의 메모리 블록을 잡고 있는 것을 보아하니 32bit 크기입니다. std::string은 당연히 s의 크기만큼 메모리 사이즈를 잡고 있을 테고, zero-length 비트 필드를 선언하고 있음으로써 bf3과 bf4는 분리되어 공간을 차지합니다.
3.4. Modification Order
모든 C++ 객체는 수정 순서(modification order)가 정의되어 있습니다. 이는 프로그램의 모든 쓰레드에 해당합니다.
The modification order may vary between executions, but in a specific execution all threads agree on the modification order of each variable.
수정 순서는 실행마다 달라질 수는 있습니다. 그러나 프로그램 실행 시 모든 쓰레드는 각각의 변수에 대한 수정 순서는 일정해야 합니다. 이게 프로그래머가 동기화를 할 때 어떠한 모델을 선택하든지 간에 신경 써 주어야 하는 부분입니다.
위의 예시를 봅시다. 만약 각 쓰레드에서 변수에 대한 수정 순서가 일정하게 약속(agreed)이 되어 있다면 모델에 따라 2번 과정의 값을 7번 과정에서 읽을 수도 있고, 없을 수도 있습니다. 약간 헷갈릴 수 있지만 여기에서는 이정도만 하고 이에 대한 내용은 아래에 서술하겠습니다.
3.5. The C++ Memory Model Without Low-Level Atomics
C++에서 기본으로 설정(default ordering model)되어 있는 모델입니다. 앞서 보았던 sequential consistent semantic 입니다. 이번 장에서는 sequentially consistent execution order과 그에 따른 엄밀한 data race의 정의를 자세히 다뤄보겠습니다.
3.5.1. Sequentially Consistent Execution
A sequentially consistent execution of a program is possible even if the chosen programming language does not implement the sequential consistency memory model.
특이한 내용입니다. sequentially consistency memory model가 적용되지 않은 언어라도 프로그램이 sequentially consistent 하도록 실행할 수 있다는 말입니다. 이번 장에서는 다중 쓰레드 프로그램이 sequential consistent 하게 실행될 경우 memory action에 어떠한 제약이 있는지 보겠습니다.

Listing 1: Evaluation of the arguments to subtract are sequenced-before the execution of the function body of subtract on line 4 but the evaluation order of the arguments to subtract is undefined. The argument evaluation contains a unsequenced side effect and the behavior of this program is therefore undefined
여기서 sequenced-before 이라는 새로운 용어를 하나 소개하고 있습니다. 의미 그대로 해석하면 ‘이전에 일어남’정도 될 겁니다. 이제까지 C++를 공부하면서 본능적으로 알고 있던 내용을 추상적으로 이론화 하여 설명하고 있습니다. 새로운 용어가 나와도 기존에 알고 있던 내용과 비교하면서 읽으면 조금 더 수월합니다.
단일 쓰레드의 실행 순서(execution order)는 sequenced-before 관계(relation)로 정의됩니다. 다시 말하면, 실행에는 어떠한 특정한 순서가 정의된다는 겁니다.
예제에 오류가 있습니다. get_num()에서 반환하는 값이 명시되어있지 않습니다.
Listing 1의 13번째 줄을 봅시다. 본론만 먼저 이야기하면 13번째의 subtract() 함수는 sequenced-before 라 할 수 있습니다. sub에 값을 대입하기 전에 subtract() 함수가 먼저 호출(called)된다는 이야기입니다. 여기까지는 자명합니다. 그리고 각각의 get_num() 함수는 subtract() 함수가 실행되기 이전에 선행되는 것 또한 명확합니다.
In general, a statement is sequenced-before another statement and the operand evaluation of an operator is unsequenced. Meaning neither operand is sequenced before the other. Exceptions to this are the built-in comma operator ‘,’ or the logical operators ‘and’ or ‘or’ where the operand evaluation is sequenced.
그러면 subtract() 함수 안의 get_num() 함수는 어떤 것이 먼저 호출되는지 의문이 듭니다. 여기서 이야기 하는 답은 ‘모른다’라는 겁니다. 연산자(operator)의 피연산자(operand) 값의 판단은 unsequenced 하다는 것입니다. subtract() 함수의 인자로 get_num() 함수가 먼저 호출되는 것은 맞지만, 앞의 것이 먼저 호출되고 뒤의 것이 호출될지, 또는 뒤의 것이 먼저 호출되고 앞의 것이 나중에 호출될지는 알 수 없습니다. 물론 비교 연산자인 and나 or 등은 순서가 명확합니다.
예제에 사소한 오류가 있지만 말하고 싶은 바는 알 수 있습니다. 이것을 unsequenced side effect라 표현하고 프로그램이 의도한 바와 같이 동작하지 않는다는 것을 말합니다(behavior of this program is therefore undefined).
To conclude, the sequenced-before relation partially orders the execution of memory actions in a single-threaded program and therefore also which value is read from a variable.
결론적으로, 싱글 쓰레드 프로그램도 부분적으로 memory action의 재정렬(reordering) 현상이 나타나는 것을 볼 수 있습니다. 여기서 memory action을 두 가지로 분류합니다. 동기화 연산(synchronization operations)과 데이터 연산(data operations)입니다.
-
As synchronization operations we define the actions: lock, unlock, atomic load, atomic store and atomic read-write-modify. All these actions can be used to communicate between threads, therefore the category name.
-
As data operations or sometimes also ordinary data operations we define the non atomic actions: store and load.
여기서 동기화 연산이란 위에서부터 계속 이야기해왔던 lock/unlock과 원자적 연산이 포함되고, 데이터 연산이란 재정렬(reordering) 방지가 보장되지 않는 일반적인 쓰기와 읽기(store and load)를 이야기합니다.
그럼 이제 몇 가지 제약 조건을 두어 다중 쓰레드 프로그램의 sequential consistent execution을 정의해 봅시다.
1) The execution of each thread must be internally consistent. This means that reordering of actions are allowed, as far as they still maintain a correct sequential execution with respect to the values read and with respect to the sequenced-before ordering. As an example, optimizations that are inconsistent with sequenced-before ordering are not allowed.
첫 번째 조건입니다. 한마디로 각 쓰레드는 내부적으로 일관성을 유지해야 한다는 것입니다. Action의 재정렬(reordering)은 허용하겠지만 그게 값을 읽고 sequenced-before을 유지해야 한다는 겁니다. sequenced-before ordering을 위반하는 최적화는 허용되지 않는다는 것을 명시하고 있습니다.
2) The total order is consistent with the sequenced-before ordering. E.g if a is sequenced before b then a <T b.
전체적인 순서는 sequenced-before 에 의해 일관성을 유지해야 한다는 겁니다. 즉, 전체적으로 sequenced-before 하라는 것입니다.
3) Each load, lock and read-modify-write operation reads the value from the last preceding write to the same location according to the total order. The last operation on a given lock preceding an unlock must be a lock operation performed by the same thread.
2번의 일관적인 total order 로부터, 수정 연산이나 lock 연산은 직전에 수행된 쓰기 연산에 의한 값을 읽습니다. 또한 unlock을 수행하기 전에는 lock을 수행해야 합니다.
이 3가지에 의해 여러 쓰레드가 수행되는 동안에도 전체적인 수행 순서(total order)는 일관성을 유지하게 될 겁니다.
3.5.2. Data Race
그렇다면 data race를 엄밀하게 정의해 봅시다.
Two operations conflict, if they access the same memory location, and at least one of them is a store, atomic store, or atomic read-modify-write operation.
Part 1에서 간단하게 이야기한 내용입니다. Part 1에서는
“적어도 두 개의 쓰레드가 동시에 하나의 공유 자료에 접근하되 둘 중 적어도 하나가 기록자(write)인 상황을 경쟁 조건(race condition)이라고 합니다.”
라고 소개한 바 있습니다. 여기서도 같은 이야기를 하고 있습니다. 조금 더 자세히 들어가면,
A data race can further be defined as: if two memory operations from different threads conflict, and ②at least one of them is a data operation, and ③the memory operations are adjacent in total order.
과 같습니다. 똑같은 이야기입니다. 다중 쓰레드에서 적어도 하나는 데이터 연산(data operation: 위에서 정의한 바와 같이 원자적 연산이 아닌 단순 load/store)이며 전체적인 순서에서 memory operation이 인접하는 경우입니다. 앞서 보았던 Figure 2의 Flag1 = 1, Flag2 == 0 과정 또한 data race인 상황입니다.
3.5.3. Data Race Free Model
앞서 이야기한 바와 같이 C++은 data race가 없는 메모리 모델입니다. 다시 바꾸어 이야기 해 보면, 위에서 data race를 정의했으므로 프로그램의 data race에 의한 동작은 반대로 정의가 되지 않습니다. 즉, 프로그램(동일한 입력에서)은 sequentially consistent 하게 명령을 수행해야 하며, 때문에 하드웨어와 컴파일러의 최적화와 재정렬(reordering)에 대한 제약이 걸립니다. 이러한 제약에 대해서는 아래에서 설명하겠습니다.
3.5.4. Optimizations Allowed By the Model
허용된 최적화에 관해 들어가기 전에 몇 가지 용어를 정리하고 갑시다.
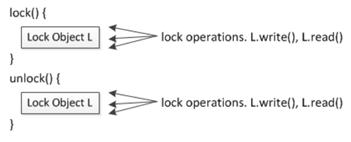
Figure 10: Lock operations are operations on the lock object. The synchronization operations lock() and unlock() use them to prevent from multiple thread in a critical section.
우선 synchronization operation을 조금 다듬어 봅시다.
The term synchronization operation is refined into: read synchronization operation that consist of lock() and atomic read and ②write synchronization operation that consist of unlock() and atomic write.
lock과 unlock은 lock 객체(lock object)를 통해 구현됩니다. 이러한 연산을 lock operation이라 하고 lock operation은 읽기나 쓰기를 수행할 수 있습니다. 여기서 이야기 하는 lock은 Part 1에서 언급한 critical section에 대한 내용과 동일합니다.
M1과 M2라는 연산이 있고, M1과 M2가 sequenced-before의 관계(relation)라면 자유롭게 재정렬(reordering) 가능합니다. 그 조건은,
- M1 is a data operation and M2 is a read synchronization operation or
- M1 is write synchronization and M2 is data or
- M1 and M2 are both data with no synchronization sequence-ordered between them
①M1이 데이터 연산이고 M2가 동기화-읽기 연산이거나, ②M1이 동기화-쓰기 연산이고 M2가 데이터 연산이거나, ③M1과 M2가 모두 동기화 없는 데이터 연산이면 하드웨어나 컴파일러가 자유롭게 재정렬(reorder)할 수 있다는 겁니다. 이를 그림으로 그려보면 아래와 같습니다.

Figure 11: Allowed reordering around synchronization operations by the described model.
추가적으로 lock operation도 재정렬이 가능한데 이는 아주 잘 구조화된(well-structured) 방식이어야만 가능합니다. dead-lock을 발생시키면 안될겁니다. 동일한 조건이라고 가정하면,
- M1 is data and M2 is the write of a lock operation or
- M1 is unlock and M2 is either a read or write of a lock.

Figure 12: Allowed reordering around lock operations by the described model.
①M1이 데이터 연산이고 M2가 lock-write 연산이거나, ②M1이 unlock을 수행하고 M2가 lock-read 또는 lock-write 연산일 때 재정렬이 가능합니다.
3.5.5. The Way to Sequential Consistent Atomics
The model requires that synchronization operations appear sequentially consistent with respect to each other
C++ 메모리 모델은 동기화 연산이 sequentially consistent 하도록 요구하고 있습니다. 즉, 동기화 연산은 다른 동기화 연산과 재정렬(reordered) 될 수 없으며, 원자적 연산(atomic operations)은 원자적으로 실행되어야 함을 보장해야 한다는 이야기입니다. 이러한 예는 Figure 2에서 이미 한번 보았습니다. Flag1과 Flag2가 원자적이지 않아 data race가 발생했었습니다.
한편으로 원자적 쓰기(atomic writes)는 성능상의 문제가 있습니다. 첫 번째로 멀티코어 프로세서에서는 쓰여진 값(written values)이 다른 코어의 캐시가 일정한 값을 가질 수 있도록 전달(propagate)되어야 합니다. 두 번째로는, 하드웨어가 임의적으로 명령(instructions)를 재정렬하지 못하도록 컴파일러가 원자적 쓰기(atomic stores)를 어떻게 변환할 것인지의 문제입니다. 대부분의 코어 제조사(vendors)가 다른 일반적인 명령어와 동기화 명령어를 구분해 두고 있지 않으니 추가적인 울타리(fence) 구현이 필요합니다.
따라서 어느 정도의 느슨한(relaxed) 원자적 쓰기 연산(atomic writes)의 구현은 성능상의 이점을 가져다줍니다.
Relaxing atomic writes means to allow reading of another thread’s write earlier than other threads can.
느슨한 원자적 쓰기 연산을 구현한다는 것은, 어느 특정한 쓰레드가 다른 쓰레드보다 먼저 쓰여진 값을 읽도록 허용한다는 의미입니다. 이건 캐시를 공유하는 멀티코어 프로세서에서는 가능합니다.
필자는 공군 작전정보통신단 체계개발실에서 복무(‘17~’19)하였습니다. 이 포스트는 작전정보통신단 병사 프로그래밍 동아리(LINK) 에서의 활동을 바탕으로 작성한 내용입니다.