C++ Multithreading (Part 3)[4]
C++ Memory Model
3.6. Introducing Low-Level Atomic to the C++ Memory Model
C++11로 오면서 명시적으로 sequential consistency 보장(guarantee)을 느슨하게 적용하는 방법이 생겼습니다. Figure 7에서의 각종 옵션이 원자적 연산이 명시적으로 로우 레벨(low-level)에서 동작하게끔 만들어줍니다. 우선 sequential consistent ordring이 표준(standard)으로 정의되어 있는 모델임을 기억하면서 다른 느슨한 모델을 봅시다.
3.6.1. Ordering Options
아래는 정렬 옵션(ordering options)의 의미를 나타내고 있습니다.
- memory_order_relaxed: no operation orders memory.
- memory_order_release, memory_order_acq_rel, and memory_order_seq_cst: a store operation performs a release operation on the affected memory location.
- memory_order_consume: a load operation performs a consume operation on the affected memory location.
- memory_order_acquire, memory_order_acq_rel, and memory_order_seq_cst: a load operation performs an acquire operation on the affected memory location.
여러 용어가 등장하니 복잡하지만 단순하게 생각해봅시다. memory_order_relaxed는 메모리를 정렬하지 않습니다. memory_order_release, memory_order_acq_rel, memory_order_seq_cst의 쓰기 연산(store operation)은 release operation을 수행하고, memory_order_acquire, memory_order_acq_rel, memory_order_seq_cst의 읽기 연산(load operation)은 acquire operation을 수행합니다.
3.6.2. Sequential Consistent Ordering
Figure 13의 간단한 예시를 봅시다. 여기서 happens-before라는 새로운 개념이 등장하고 있습니다.

Figure 13: Sequential consistent ordering. Each thread reads the others write atomically.
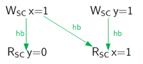
Figure 14: Happens-before relation between operations in the example of Figure 13.
Figure 13은 data race가 발생하지 않습니다. 이는 happens-before 관계로 보일 수가 있는데, 이 개념 또한 문자 그대로 받아들이면 편합니다. 해석하면 ‘일어나기 전에’정도 될 겁니다. 쓰레드 내부에서는 happens-before은 sequenced-before과 동일하다고 보면 됩니다.
Figure 13은 data race가 발생하지 않습니다. 이는 happens-before 관계로 보일 수가 있는데, 이 개념 또한 문자 그대로 받아들이면 편합니다. 해석하면 ‘일어나기 전에’정도 될 겁니다. 쓰레드 내부에서는 happens-before은 sequenced-before과 동일하다고 보면 됩니다.
쓰레드 간의 관계(inter-thread consideration)의 입장에서 봅시다. x.load 연산은 x.write 연산과 동기화 관계에 있습니다. load연산이 write 연산의 결과를 읽는 과정이니까요. 단순화된 정의에 의하면 release operation W(write의 약자)는 W에 의해 쓰여진 값을 읽는 acquire operation과 synchronizes-with 관계에 있습니다. 더 나아가 생각하면 synchronizes-with 관계에 의해 inter-thread-happens-before의 관계가 생기고, 결국 happens-before 관계로 나아갑니다.
새로운 용어는 문자 그대로 해석하면 편합니다. 좋은 번역 방법이 떠오르지 않네요.
조금 풀어서 설명해 봅시다. Figure 14에서 왼쪽의 Wscx(x.store)는 Rscy(y.load) 보다 먼저 일어나므로 sequenced-before 관계에 있습니다. 하나의 쓰레드 내에 있기 때문에 위의 설명에서처럼 happens-before 관계에 있다고 봐도 무방할 것입니다. 이는 Figure 14의 오른쪽 쓰레드에서도 동일하게 적용됩니다. Wscy(y.store)는 Rscx(x.load) 보다 먼저 일어나므로 sequenced-before 관계이고, 동일한 쓰레드 내의 관계이므로 happens-before입니다.
계속해 봅시다. release operation은 acquire operation과 synchronizes-with 관계에 있기 때문에 결국 Wscx(x.store)이 먼저 선행되고 Rscx(x.load)가 나중에 일어납니다. 즉, 이는 inter-thread-happens-before, sequenced-before 관계임과 동시에 happens-before 관계에 놓여 있습니다. 이를 정리한 내용이 바로 아래입니다.
Further inter-thread-happens-before also combines with the sequenced-before relation: if operation A is sequenced before operation B, and operation B inter-thread happens-before operation C, then A inter-thread happens-before C.
A가 B보다 먼저 선행(sequenced-before)되고, 서로 다른 쓰레드에서 B가 C보다 먼저 선행(inter-thread-happens-before)된다면 A는 C보다 먼저 선행(inter-thread-happens-before)된다는 이야기입니다. 당연한 이야기이지만 뭔가 장황하게 써 두었습니다.
그러면 여기서 happens-before의 관계를 이용해 새로운 data race의 정의를 유도할 수 있습니다.
A data race can now newly be defined with the happens-before relation as follows: Two actions at the same location, on different threads, not related by happens-before and at least one of which is a write.
두 행동이 동일한 메모리 위치에 접근하는데, happens-before로 엮이지 않으면서 둘 중 하나가 적어도 기록자(write)면 data race가 발생합니다. happens-before로 엮이지 않는다는 말을 달리 하면 두 개의 명령 수행이 일정한 순서가 보장되지 않음을 의미할겁니다.
3.6.3. Relaxed Ordering
느슨한 정렬(relaxed ordering)은 C++ 메모리 모델 중에서 가장 약한(weakest) 정렬 모델(ordering model)입니다. relaxed ordering은 모든 쓰레드가 각자의 변수 수정에 대한 순서를 변화시키는 것만 보장합니다. 예를 들어 Figure 15는 Figure 13과 동일한 프로그램입니다. 단지 relaxed로 옵션이 변경되었을 뿐입니다.

Figure 15: Relaxed ordering. Each thread reads the others write atomically.

Figure 16: Possible outcome for each operation in the program of Figure 15. As relaxed atomics do not contribute in synchronization, there is no happens-before relation between variable that are shared by threads.
그림에서와 같이 x의 변수를 읽으면 0의 값이 나올 가능성이 있습니다.
This result is possible since there is no imposed ordering between the read and write on the shared variable x.
당연히, 적용된 순서 모델(ordering)이 없으니 쓰레드 변수 간의 happens-before의 관계가 성립하지 않습니다. 따라서 Figure 16과 같은 결과가 나올 수 있습니다. (무조건 Figure 16의 결과가 나온다는 것이 아니라 나올 수 있는 하나의 경우의 수입니다.) 물론 이와 같은 상황에서는 data race가 존재하지 않을 겁니다.
3.6.4. Acquire-Release Ordering
acquire-release ordering은 sequential consistency보다는 조금 느슨(relaxed)합니다.
There is no guarantee anymore, that a read of a location returns the last previously written value.
이 모델은 어느 한 곳의 읽기 연산의 결과가 이전에 쓰였던 값이라는 것을 보장하지 않습니다. 이는 release sequence를 이용한 synchronizes-with 관계를 조금 더 정교화 시키면 가능합니다.
Additionally the possible value read by the acquire operation that participates in synchronizes-with are defined by the visible sequence of side effects.
추가적으로 봅시다. synchronizes-with 관계에 있는 상태의 acquire operation을 이용하여 값을 읽는 경우, 그 값은 visible sequence of side effects에 의해 정의된다고 합니다. 이는 예시를 보면서 설명하겠습니다.
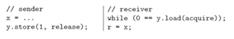
Figure 17: The release operation of the sender on y synchronizes-with the acquire operation on y by the receiver.

Figure 18: (1) shows the synchronizes-with relation. (2) shows the synchronizes-with relation with a release sequence.
Figure 17을 봅시다. 송신자(sender)와 수신자(receiver)가 있습니다. 송신자가 x에 1이라는 값을 쓰기까지 while문을 돌며 y flag가 설정(set)될 때까지 기다리는 구조입니다. 여기서 수신자는 반드시 송신자가 쓴 값을 읽는 것을 보장받아야 하고, 추가적으로 수신자가 읽기 전까지 x 변수의 값이 수정되면 안 됩니다. Figure 17은 이 내용이 보장되는 것을 확인할 수 있습니다.
The synchronizes-with edge arises because of the acquire operation (c) that reads from the release operation (b).
여기서 edge라 함은 ‘신호를 보낸다’ 정도로 이해하면 됩니다. 당연히, release operation이 완료되면 synchronizes-with 의 관계에 있어 신호를 보내고, acquire operation(RACQy)은 release operation의 결과 값을 읽습니다. 여기서 release sequence는 아래와 같이 이해하면 됩니다.
By the release sequence it is defined that an acquire operation can synchronize with a release (to the same location), that is before the write that it reads from.
release sequence에 의해 acquire operation은 release operation에 의해 쓰여진 값을 읽습니다. 조금 더 자세히 정의하면
A release sequence is defined as a contiguous sub-sequence of modification order on the location of the release. The release sequence is headed by the release (e.g (b)) and can be followed by writes from the same thread (e.g (c)) or read-modify-writes from any thread (not shown).
한마디로 release가 행해지고 난 뒤의 인접한 수정 절차(modification order)라고 이해하면 됩니다. Figure 18의 ①번은 문제없이 (b)의 release operation에 의해 저장된 값을 읽습(acquire operation)니다(synchronizes-with). 그런데 ②의 경우는 (d)의 읽는 행위(aquire operation, RACQy)는 release operation의 값을 읽을 수 없습니다. 여기서 등장하는게 위에서 보았던 visual sequence of side effects입니다. synchronizes-with 관계에 있는 acquire operation의 결과는 visual sequence of side effects에 의해 정의된다는 겁니다.
Which values can be read by the acquire participating in synchronizes-with is defined by the visual sequence of side effects.
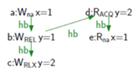
Figure 19: Happens-before relation in program fragment of Figure 18 (2).
자세히 봅시다. Figure 19는 Figure 18 2번의 그림을 happens-before 관계로 나타낸 그림입니다. visual sequence of side effects를 정의해 보면,
A visual sequence of side effects of a read is a contiguous sub-sequence of modification order, headed by a visible side effect of the read, where the read does not happen before any member of the sequence.
아하, 이제 조금 알겠습니다. visual sequence of side effects란 순서의 가시성이 입장에 따라 달라짐을 이야기합니다. Figure 19에서 d:RACQy 과정은 b:WRELy의 입장에서 ‘보입’니다(visible). 그러나 c:WRLXLy은 보이지 않습니다. (b)과정과 (c)과정은 happens-before 관계에 있고, (b)과정과 (d)과정도 happens-before 관계에 있습니다. (c)와 (d)입장에서는 서로 볼 수가 없습니다. 또한 (c)과정은 단순히 relaxed operation 입니다. 따라서 (e)번에서 읽는 행위는 (c)의 결과와 (d)의 결과 모두 불러올 수 있습니다.
3.6.5. Data Dependency in Acquire-Release Ordering
sequential consistency보다 상대적으로 약한(weaker) 메모리 순서(memory order)인 release/acquire 쌍(pair)(acquire-release ordering)이라면 멀티 프로세서에서의 구현은 비용이 좀 더 저렴합니다. 그렇지만 이 또한 단순한 저장과 읽기(plain stores and loads)보다는 조금 더 비용을 지불해야 될겁니다.
Multiprocessors as Power guarantees that certain data dependencies in instructions are respected.
여기서 Power의 의미를 정확히는 모르겠지만, 여하튼 특정한 멀티프로세서는 명령어의 데이터 의존성(data dependencies)을 보장한다고 합니다. 따라서 이러한 경우에는 동기화에서의 재정렬 방지를 위한 각종 노력이 쓸모가 없습니다. 추가적인 노력을 들이지 않아도 된다면 성능상의 이점 또한 가져올 수 있을 겁니다. 이러한 이유 때문에 acquire-release ordering에 memory_order_consume이 도입된 이유입니다. 만일 프로그래머가 하드웨어(target hardware)가 데이터 의존성에 의해 특정한 순서를 보장한다면 굳이 이외의 모델을 적용하지 않고 memory_order_consume을 적용한다면 추가적인 동기화 비용을 지불하지 않고서도 충분할 겁니다.
memory_order_consume의 예시는 아래에서 봅시다.

Figure 20: Write data and store to a shared atomic pointer p by the sender. The receiver consumes the shared pointer and dereferences.

Figure 21: (1) shows the synchronizes-with relation in release/acquire pairs. (2) shows the dependency-ordered-before (dob) relation between the release operation (b) and the consume operation (c) as well as to (d) because (c) carries-a-dependency-to (d).
Figure 20을 보면 송신자(sender)는 data 변수에 값을 저장(store)하고 공유 원자적 포인터(shared atomic pointer) p에 그 값을 넘기고 있습니다. 수신자(receiver)는 포인터의 값을 읽고 있습니다. 이에 대한 관계는 Figure 21에 나타나 있습니다. ②번은 memory_order_consume을 적용했을 경우에서의 그림이고, 비교를 위해 ①번은 memory_order_acquire을 적용했을 때를 그려주었습니다.
다시, carries-a-dependency-to라는 새로운 개념이 등장합니다. 이 또한 문자 그대로 해석해봅시다. ‘의존한다’ 정도면 충분할 듯 합니다. 정리해보면,
The read of p (c) carries-a-dependency-to the read of the data (d). The relation carries-dependency-to applies only within a single thread and models data dependency between operations.
(d)의 읽는 과정이 (c )의 읽는 과정에 의존하고 있습니다. 단적으로 코드만 봐도, 주소를 넘김으로써 그 주소에 의존하고 있다고 이해해도 좋습니다.
If the result of an operation A is used as an operand for an operation B, then A carries-a-dependency to B.
어렵게 써 놨지만 간단히 이야기 하자면 이겁니다. B 연산에 A 연산의 결과가 피연산자로 쓰인다면 B는 A연산에 의존하고 있다고 봐도 무방하다는 겁니다.
If the result of operation A is a value of a scalar type such as an int, then the relationship still applies if the result of A is stored in a variable, and that variable is then used as an operand for operation B
같은 말입니다. 만일 A 연산의 결과가 스칼라 타입(즉, 상수)이고 그 결과가 B의 연산에 쓰인다면 마찬가지로 B는 A연산에 의존하고 있을 겁니다. (위의 예에서 (c)와 (d)의 관계)
dependency-ordered-before라는 개념도 등장합니다. 읽어보면 release/acquire synchronizes-with 관계와 비슷한 놈입니다. 이는 이미 위에서 훑고 왔었습니다.
The dependency-ordered-before is the release/consume analogue of the release/acquire synchronizes-with.
비슷한 놈이라면, 당연히 dependency-ordered-before 요 놈도 release sequence를 포함하고 있을 겁니다. 위의 예에서 (b)에 해당합니다. 따라서 (c)에서 읽힐 수 있는 값은 또 다시 visual sequence of side effects에 의해 정의됩니다. 더 나아가면 dependency-ordered-before 관계는 inter-thread-happens-before에 기여하고, 그러므로 happens-before 또한 마찬가지입니다.
3.6.6. Example - Reading Values From a Queue
앞서 보았던 내용에 의하면 release는 acquire와 동기화(synchronize)할 수 있는데, acquire에서 읽는 값은 release의 결과를 읽는 것이 보장되지는 않습니다. 그러나 읽는 값은 무조건 release sequence의 결과여야만 합니다.
Other threads can participate in the release sequence if there are read-modify-write operations executed between the release and the acquire of the synchronizes-with relation.
다른 쓰레드가 read-modify-write operations가 있는 경우 release/acquire synchronizes-with의 release sequence 사이에 작동할 수 있다고 합니다. 하나의 쓰레드가 큐에 내용을 채우는(populate) 동안 다른 쓰레드는 내용을 읽어 들이는 예시를 봅시다.

Listing 2: Reading from a queue with atomic operations. The full example can be seen in Listing 3 on page 17 in the appendix.
count는 원자적 자료 형식입니다. 8번 줄을 보면 초기 아이템의 개수를 저장하고 있습니다. release이므로 다른 쓰레드에게 내용이 준비되었다는 것을 알릴 수 있을 겁니다. 다른 쓰레드에서 이제 이 값을 읽기 시작할 것입니다. 우선 read-modify-write operation(여기서 fetch_sub() 함수, acquire semantic)을 통해 값을 달라고 요청합니다.
fetch_sub() 함수는 원자적으로 count 변수를 읽고 count 변수에서 1을 빼서 count에 반영합니다. 그리고 리턴 된 값은 수정되기 전에 읽힌 값입니다. 0보다 작은 값이 리턴 된다면 while문을 돌면서 새로운 아이템이 큐에 채워질 때 까지 기다릴 겁니다. 과정을 그림으로 나타내면 아래와 같이 될 것입니다.
그림에서 점선은 release sequence를 나타내고 실선은 happens-before 관계를 나타냅니다. 처음의 fetch_sub() 함수는 release sequence 이므로 두 번째 fetch_sub() 함수의 호출과 동기화 됩니다.
Recognize also that the value read by the second fetch_sub must return the value written by the first fetch_sub although both, the release and the first acquire, are in the visual sequence of side effects.
여기서 자세히 보면 두 번째 fetch_sub()는 첫 번째 fetch_sub()에서 수정한 count 값을 리턴해야 됩니다. 그런데 release와 첫 번째 acquire가 visual sequence side effects입니다. 즉, count.store()에 의해 일어난 count 변수의 수정과 fetch_sub()에 의한 count 변수의 수정 중 어느 값을 읽어야 하는지 모호합니다.
This is defined by the write-read coherence that prevents from reading a value that is happens-before hidden by a later write in the modification order. To our case, the release (write) is hidden to the second acquire since the release happens before the second acquire and the first acquire occurs later in the modification order of count.
write-read coherence, 즉 수정 과정에서 나중에 일어날 쓰는 과정에 의해 숨겨진 happens-before 관계에 있는 값을 읽는 것을 방해하는 것을 이야기하고 있습니다. 이 예시의 경우 release는 두 번째 acquire에 숨겨져 있는 상태입니다.
4. Conclusion
프로그램을 작성할 때 data race가 일어나지 않도록 하는 것이 가장 중요합니다. 순서 옵션(ordering option)을 적용하지 않는다면 sequential consistent execution은 C++11에 정의된 메모리 모델에 의해 항상 보장됩니다. 따라서 대부분의 경우 컴파일러의 제멋대로인 최적화나 하드웨어의 모델을 신경쓰지 않아도 무방합니다.
만일 lock과 sequential consistent atomics에 의한 sequential consistent execution이 만족할만한 성능을 뽑아내 주지 않는다면 로우 레벨(low-level) atomics를 적용할 수 있을 겁니다. 그렇지만 위의 경우에서 보았듯이 조심해서 사용해야 할 겁니다.
후, 직접 해석과 기술적 이해를 동시에 하고 글로 옮기려니 굉장히 힘이 듭니다. 이 자료를 작성하면서 모호한 부분도 있고 이해가 잘못된 부분 도 있고 각종 오류가 있을 수 있습니다. 또 억지스러운 해석으로 인해 표현이 자연스럽지 못 한 부분도 굉장히 많습니다. 따라서 원문을 보는 것을 추천 드리며 이 자료와 같이 첨부하겠습니다.
얼떨결에 Part 3를 먼저 작성했는데 너무 피곤하네요. 과연 Part 2를 마저 작성할 수 있을지…
필자는 공군 작전정보통신단 체계개발실에서 복무(‘17~’19)하였습니다. 이 포스트는 작전정보통신단 병사 프로그래밍 동아리(LINK) 에서의 활동을 바탕으로 작성한 내용입니다.