[조사 노트] Consistency Models
이 포스트는 OSLab 연구 활동에서 작성한 개인 노트의 일부입니다. 공부 목적으로 작성된 내용이므로 많이 부족할 수 있습니다.
Consistency Models
Consistency Model 은 각기 다른 시멘틱(Semantics)를 보장한다. Consistency Model 은 참여자(Participant) 사이의 일종의 계약(contract)이라 생각할 수 있다: 각 복제본(Replica)은 조건을 만족하기 위해 어떠한 행위를 해야 하며, 클라이언트 혹은 사용자는 Read/Write에 대해 어떠한 결과를 기대할 수 있는지를 약속한다.
Ordering
Consistency Model 을 알아보기 전에, 순서(Order)의 정의를 짚고 넘어가야 한다. 분산 시스템에서는 어떠한 이벤트가 언제 일어났는지, 그리고 이에 대한 정보가 클러스터 사이에 공유되는지의 여부를 알기 힘들다. 따라서 모든 연산은 두 가지의 관점에서 범위(Bound)를 제한한하는데, 이를 개시(Invocation)와 완료(Completion)로 구분한다.
여러 개의 프로세스가 읽기/쓰기(Read/Write)를 수행할 때 잠재적인 문제점은 다음과 같다.
- 중첩된 연산 “Operations may overlap.”
- 중첩되지 않은 호출의 결과는 즉시 보이지 않을 수 있다. “Effects of the nonoverlapping calls might not be visible immediately.”
Types of Consistency
분산 시스템, 혹은 Shared Memory 에서의 Consistency 는 보장 정도에 따라 두 가지로 나눌 수 있다.
-
Strict Consistency : “Any read on a data item x returns a value corresponding to the result of the most recent write on x.”
모든 프로세서는 항상 과거에 쓰여진 최신의 데이터를 즉시 읽을 수 있다. Strict Consistency 의 특징은 즉각적인 (instantaneous) 결과 반영 (Write, 혹은 메세지 교환)이다. Strict Consistency 의 모델의 구현은 완벽히 동기화 되는 (synchronized) 전역적 절대 시간 (Global Absolute Clock)을 필요로 한다.
그러나 이 모델은 구현하는 것이 불가능한 이론적인 모델이다.
-
Non-strict Consistency : Strict Consistency 의 필요 조건을 완화하여 정의하는 모델이다.
Sequential Consistency
“… the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.”
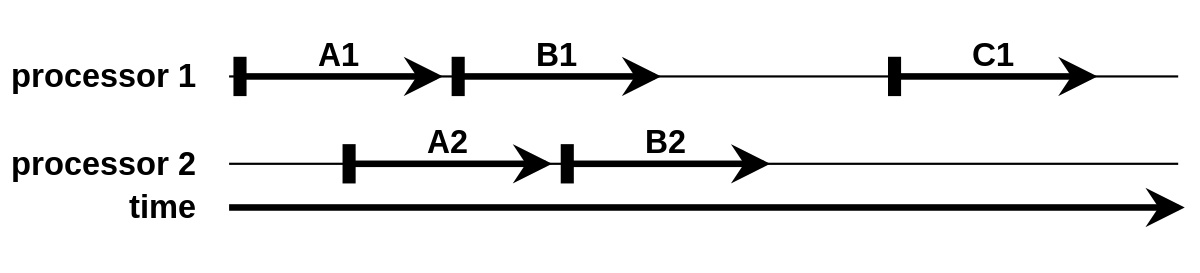
Sequential Consistency 는 Strict Consistency 에 비해 완화된 모델이다. 특징은 시간에 대한 조건이 없다는 것에 있으나, 순서의 주요 기준은 프로그램의 순서이다. 여기서 프로그램이란, 각 프로세스가 수행하는 프로그램을 의미한다. 각 프로세서는 독립적으로 프로그램을 수행하므로 프로세스 간의 순서는 정의하지 않는다.
동기화되는 전역적 절대 시간 (Global Absolute Clock), 혹은 쓰기(Write) 행위의 즉각적 가시성을 요구하지는 않으며 다른 프로세서에 동일한 순서로 보여야 한다. 단,
Sequenctial Consistency 는 다음과 같은 조건을 요구한다.
-
Program order (프로그램 순서 보장) : “Program order guarantees that each process issues a memory request ordered by its program.”
각 프로세서가 메모리 요청을 순서대로 수행하도록 보장한다. 클라이언트 하나의 연산의 순서 (프로그램 순서)는 시간적 순서를 따른다.
-
Write atomicity (원자적 쓰기 연산) : “Write atomicity defines that memory requests are serviced based on the order of a single FIFO queue.”
쓰기 원자성은 단일 FIFO Queue 를 통해 도착 순서대로 메모리 접근이 이루어져야 한다는 것을 정의하고 있다.
Sequential Consistency 를 만족하는 경우, 각 클라이언트의 요청이 순서만 보장 된다면 어떠한 순서로도 처리가 가능하지만, Linearizability 를 만족하는 경우 시간에 따라 순서가 결정된다.
Linearizability (Atomic Consistency)
Linearizability 는 시간적 조건이 없는 Sequential Consistency 에서, 시간에 대한 조건이 추가된 Consistency Model 이다. Linearizability 는 강력한 (strong) 단일 오브젝트 (single-object), 단일 연산 (single-operation) 의 Consistency Model 이다.
“… the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.” (Sequential Consistency) 에 다음이 추가된다.
$TS_{operation1}(x) < TS_{operation2}(x)$ 이라면 Operation 1 이 Operation 2 보다 우선된다.
Linearizability 의 특징은 다음과 같다.
- Atomicity : 연산은 개시 (Invocation)부터 완료 (Completion) 시점 까지 그 사이에 어딘가에 원자성을 가지며 실행된다. 어떠한 연산도 그 즉시 실행되지는 않는다.
- Single Copy : 많은 복제본(Replica)이 존재하더라도 데이터는 단일 복사본 (single copy)에 대해 연산을 실행하는 것처럼 보인다.
중첩된 (Overlapped) 연산에 대해서는 Linearizability 는 어떠한 순서로도 실행될 수 있다. 단, 연속적(sequential)인 결과를 보여준다.
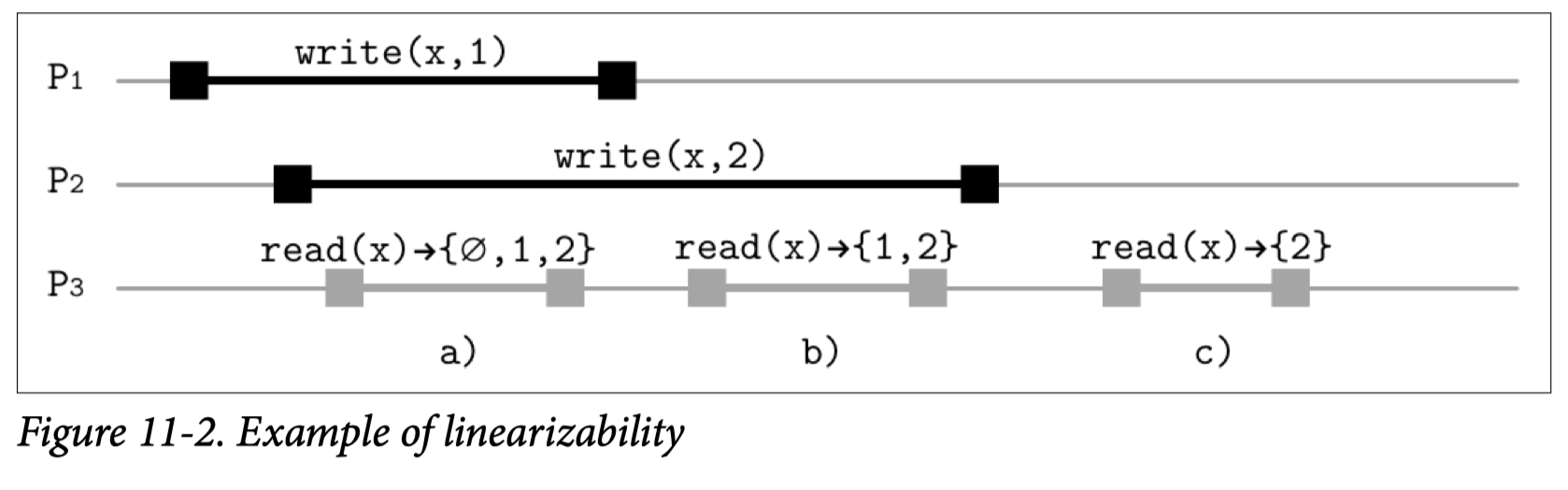
위의 예시를 들어서 설명하자.
- 초기의 값이 NULL 이라 가정하자.
write(x, 1)과write(x, 2)가 중첩된 상태에서 a)의read(x)는NULL,1,2중 어떠한 값도 읽을 수 있다.read(x)연산은 두 쓰기 연산이 완료되기 이전에 실행된다. 이는 Linearizability 의 Atomicity 특성에 의해, 개시(Incovation)와 완료(Completion) 사이에 원자적 쓰기 연산이 실행되기 때문이다. - 두 번째 b)
read(x)는 첫 번째write(x, 1)가 완료 (Completion) 되었으므로1,2모두 읽을 수 있다. - 세 번째 c)
read(x)는 두 개의 쓰기 연산이 모두 완료 (Completion) 되었으므로2만 읽을 수 있다.
Linearizability 는 Serializability 와 구분되는 개념으로, Serializability 는 순서에 대해 보장할 뿐 그 순서를 정의하지는 않는다. 반면, Linearizability 는 어떠한 값이 읽혀(Read)야 하는지를 정의한다.
- “Serializability means that transactions have the same effect as if they had been executed in some serial order, but it does not define what that order should be.” 즉, Sequencial Consistency 는 클라이언트 간의 연산에 대한 순서 재정렬 (reordering)이 가능하다.
- “Linearizability defines the values that operations must return, depending on the concurrency and relative ordering of those operations.” 즉, Linearizability 는 클라이언트 간의 연산에 대한 순서는 시간 (Timestamp)에 따른다.
한편, Linearizability 와 Serializability 가 가지는 공통의 속성은 다음과 같다.
- Single Copy : 많은 복제본(Replica) 또는 노드가 존재하더라도 마치 단일 복사본, 또는 단일 노드에 대해 연산을 실행하는 것처럼 보인다.
- 다음의 쓰기 (Write) 연산이 있기 전까지의 읽기(Read)에 대해서는 가장 최신의 결과를 반환하며, 모든 클라이언트가 동일한 결과값을 반환받는다.
Causal Consistency
Causal Consistency 모델은 완화된 Sequential Consistency 의 형태이다.
“It defines that only write operations that are causally related, need to be seen in the same order by all processes.”
“Causal consistency captures the potential causal relationships between operations, and guarantees that all processes observe causally-related operations in a common order. In other words, all processes in the system agree on the order of the causally-related operations.”
Causal Consistency 는 Program Order 에 기반하는 것이 아닌, 인과 관계 순서 (Causal Order)에 기반한 연산의 순서만 보장한다. 인과 관계 순서가 아닌 연산에 대한 순서는 클라이언트마다 다르게 보아도 상관없다.
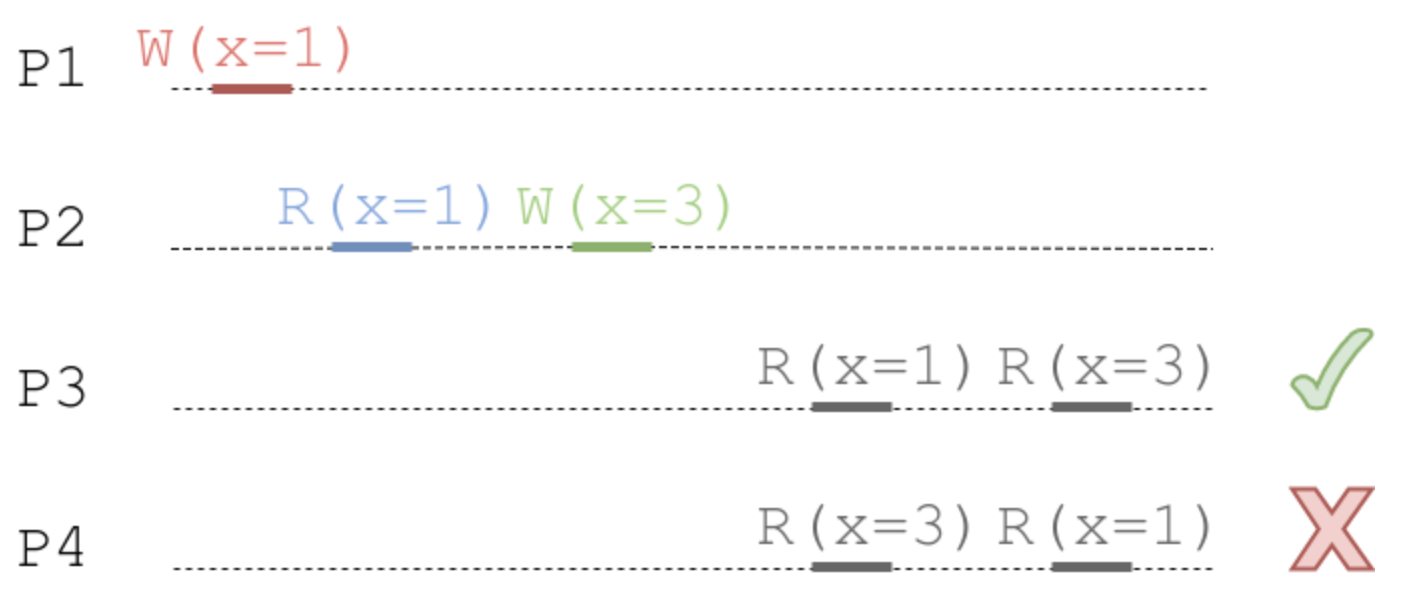
위의 예시에서, 만일 W(x=1) 이후의 W(x=3) 연산이 서로 인과 관계(Causally Related)를 가지고 있다고 하자. P3의 경우, 이 인과 관계 순서에 따라 R(x=1), R(x=3) 순서로 읽었으므로 Causal Consistency 를 만족하며, P4는 만족하지 않는다.
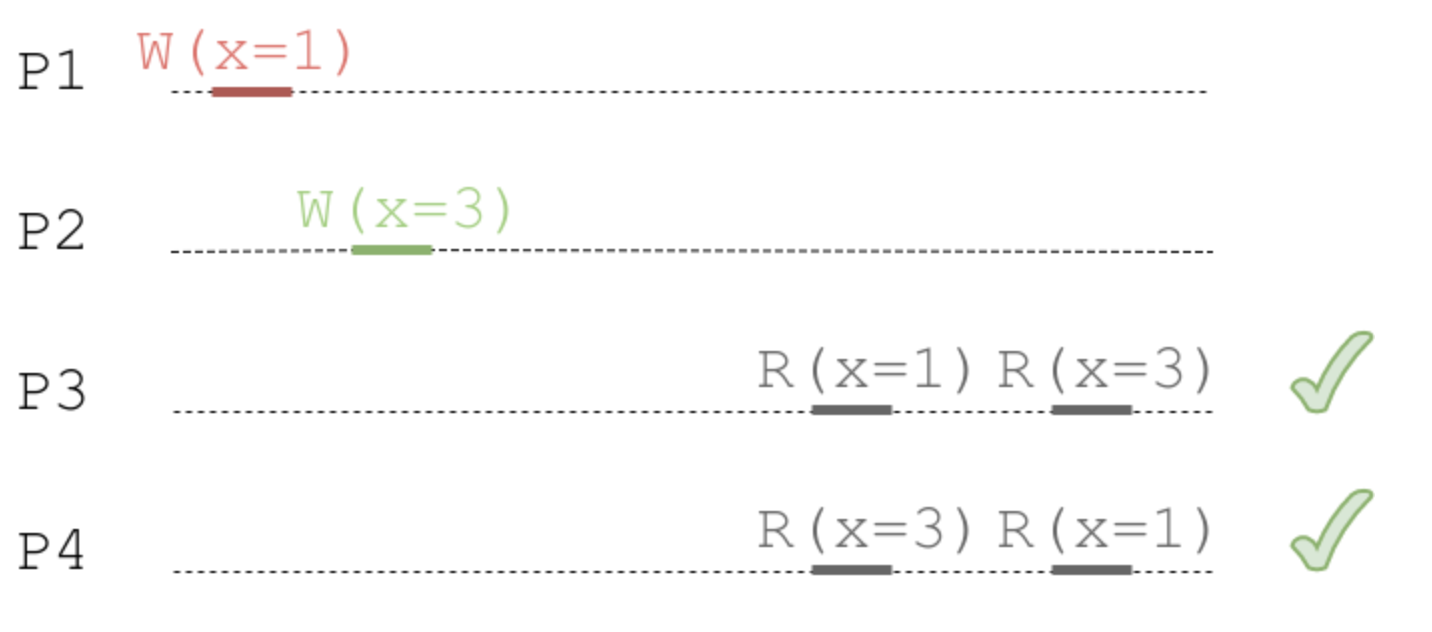
그러나 두 번째 예시에서 만일 W(x=1) 이후의 W(x=3) 연산이 서로 인과 관계 순서가 없다고 가정하면, Causal Consistency 에서는 R(x=1)과 R(x=3)에 대한 읽기 연산의 순서는 보장하지 않는다. 따라서 P3와 P4 모두 Causal Consistency 를 위반하지 않는다.
Eventual Consistency
Linearizability 모델은 강력한 일관성 모델 (Strong Consistency Model) 이지만, 이를 지원하기 위해서는 다음과 같은 문제가 존재한다.
- Performance Cost : 많은 메세지 교환, 또는 이와 함께 수반되는 네트워크 지연이 존재할 수 있다.
- Scalability Limits : 리더 (Leader)가 병목의 원인이 될 수 있다.
- Availability : 쿼럼(Quorum)의 합의가 없다면 다음 단계로의 진행이 불가능하다.
Eventual Consistency 는 아래의 특성을 이용해 조건을 완화한 Consistency Model 이다.
“If no new updates are made to an object, eventually all reads will return the last updated value.”
Eventual consistency 는 항목이 새롭게 업데이트 되지 않는다면, 모든 읽기 (Read) 작업이 최종적으로는 마지막으로 업데이트된 값을 반환한다는 것을 보장하는 모델이다.
단, 결과적(eventually)으로 최신의 값이 되는 것에 대한 제약을 두고 있지 않기 때문에 (e.g. 만일 지속적으로 쓰기(Write)에 대한 행위가 이루어지는 경우) 완화된 (Relaxed) 형태의 정의라고 할 수 있다. 따라서, 강화된 Eventual Consistency 는 다음과 같은 조건을 추가하여 정의한다.
-
Eventual Delivery : “Every update made to one non-faulty replica is eventually processed by every non-faulty replica.”
장애가 발생하지 않은 복제본(Replica)으로 요청된 업데이트는 결과적으로 모든 복제본(Replica)에서 처리된다.
-
Convergence : “Any two replicas that have processed the same set of updates are in the same state (even if updates were processed in a different order).”
동일한 업데이트 요청을 처리한 임의의 두 복제본 (Replica)는 동일한 상태에 도달한다.
Serializability
Linearizability 는 Serializablity 의 좁은 개념이다. 둘의 주요 차이점은 다음과 같다.
-
Linearizability : “It doesn’t involve “transaction”, which groups multiple objects. It treats each operation as an atom, i.e. to take effect in a single time point, rather than a timespan.”
“Linearizability is a recency guarantee. Once a writer sets new value, the value immediately takes effect. All readers immediately see the new value. Readers always read the newest value. Operations in Linearizability are by nature total ordered, and there are no concurrenct operations.”
Linearizability 는 단일 오브젝트를 대상으로 한다. 각각의 연산의 원자성, 전순서(Total Order)를 보장하며, 읽는(Read) 행위는 항상 가장 최신의 값을 반환받는다.
-
Serializability : “Serializability is an isolation level for database transactions. It comes from database community area, where is a different area that Linearizability originates. Serializability describes multiple transactions, where a transaction is usually composed of multiple operations on multiple objects.
“Database can executed transactions in parallel. Serializability guarantees the result is the same with, as if the transactions were executed one by one. i.e. to behave like executed in a serial order.”
“Serializability doesn’t guarantee the resulting serial order respects recency. i.e. the serial order can be different from the order in which transactions were actually executed. That is also to say, to satisfy the same Serializability, there can be more than one possible execution schedulings.”
Serializability 는 데이터베이스 영역에서 분리(isolation)의 개념에서 출발한다. 이는 병렬로 실행되는 각각의 트랜잭션(Transaction)이 일정한 순서를 가지고 순차적으로 실행되는 것을 보장한다. 단, 이러한 직렬 순서 (Serial Order)가 가장 최신의 값을 갖도록 하지는 (Recency) 않는다.
Clocks
분산 시스템에서 완벽히 동기화되는 전역적 시간 (Global Absolute Clock)은 존재할 수 없다. 따라서 논리적 시간 (Logical Clock)을 사용하는데, 두 개의 차이점은 다음과 같다.
- Physical Clock : 몇 초가 지났는지를 기록하는 카운터 값
- Logical Clock : 이벤트(Event)가 발생한 횟수를 기록하는 카운터 값
오차가 존재하는 물리적인 시간 (Physial Clock) 과는 다르게, 논리적 시간(Logical Clock)은 이벤트(Event) 발생의 순서를 추척하는데 집중한다.
Logical Clock Algorithm
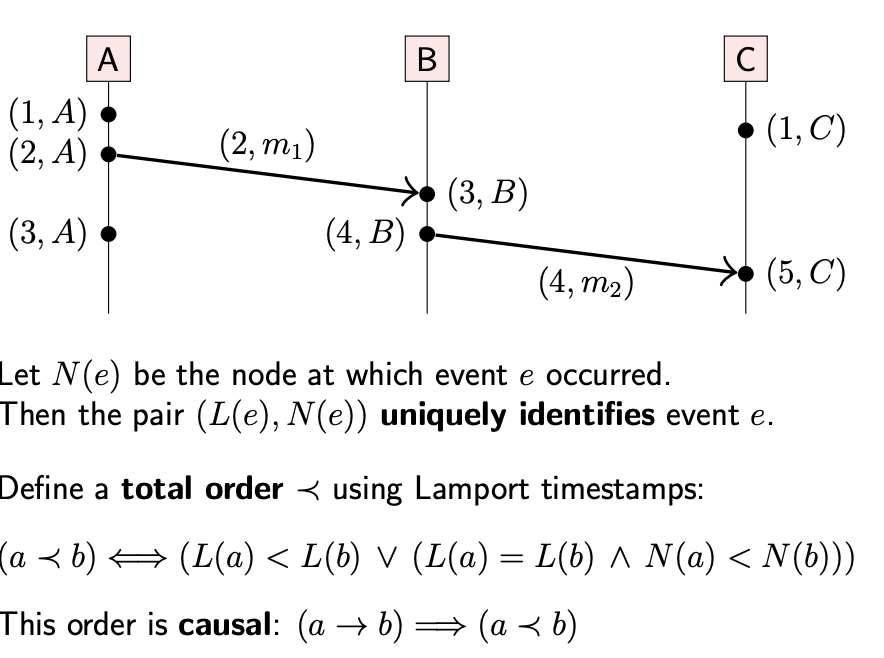
Lamport 가 제시한 논리적 시간(Logical Clock) 알고리즘은 다음과 같다.

각각의 노드는 자신의 로컬 변수 $t$를 보유한다. 이벤트가 발생할 때 마다 카운터를 증가시키고, 메세지에 이 카운터 값을 추가하여 전송한다. 메세지 수신측은 송신측의 카운터 변수를 보고, 자신의 값 $t’$와 비교하여 이 값 보다 큰 값으로 로컬 변수를 수정한다.
Vector Clock Algorithm
어떠한 두 이벤트 $a$, $b$ 가 있다고 가정하자. 만일 $L(e)$ 가 특정 이벤트 $e$ 이후에 증가된 카운터 값이라고 할 때, 두 값 $L(a)$, $L(b)$ 가 주어졌을 때 $a$와 $b$ 중 어떠한 이벤트가 선행되었다고 판단이 가능한가의 문제가 존재한다. 따라서 시간에 대한 표현을 벡터 형식으로 생성하면서 이 문제점을 해결한다.
이에 대한 알고리즘은 다음과 같다.

N개의 노드가 존재한다고 할 때, 변수 $t$ 대신 $<N_1, N_2, …, N_n>$ 의 벡터 형식의 로컬 카운터를 가진다. 벡터의 각 항목은 각 노드가 알고 있는 다른 노드 $i$에 대한 카운터를 저장한다.
이벤트가 발생하면 자신의 벡터 항목 카운터를 증가시키고, 메세지에 이 벡터 값을 추가하여 전송한다. 수신측은 전달 받은 벡터에 기반하여, 각 벡터 항목과 비교하여 자신의 벡터 값을 증가시킨다.
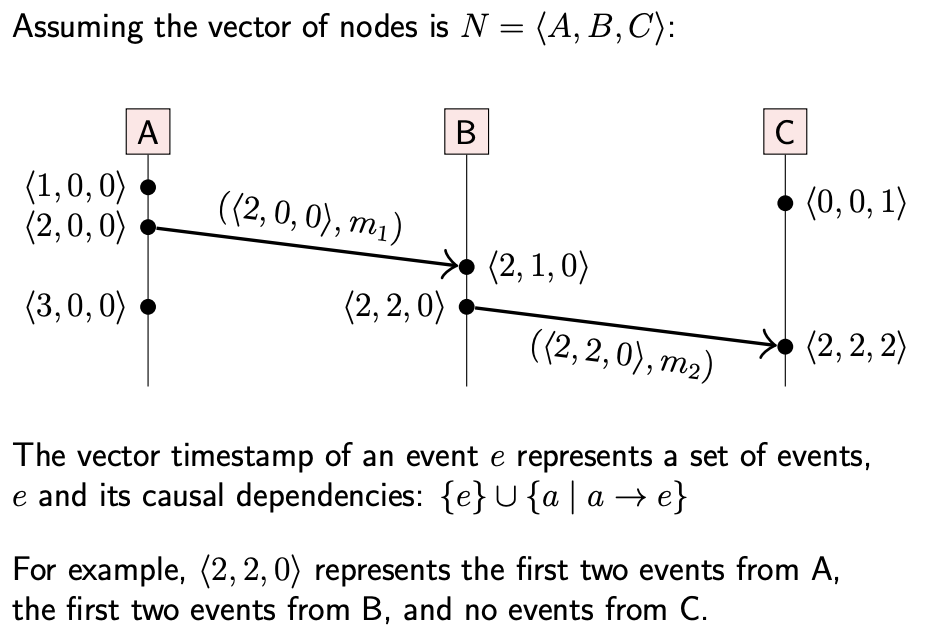
타임스탬프(Timestamp) (벡터 값)의 비교의 경우 벡터의 모든 항목이 다른 벡터의 항목보다 큰 경우 Partial Order 를 결정할 수 있다. 만일 일부의 항목은 크지만 다른 항목이 작은 값을 가진 경우에는 순서를 비교할 수 없다.
Reference
- Shared Memory Consistency Model
- https://www.cs.colostate.edu/~cs551/CourseNotes/Consistency/TypesConsistency.html
- Wikipedia - Consistency Model
- MariaDB - Causal Consistency
- Linearizability vs Serializability, and Distributed Transactions
- https://cse.buffalo.edu/~stevko/courses/cse486/spring13/lectures/26-consistency2.pdf
- https://www.cs.helsinki.fi/webfm_send/1256
- https://www.cl.cam.ac.uk/teaching/2122/ConcDisSys/dist-sys-notes.pdf
- Database Internals - A Deep Dive into How Distributed Data Systems Work - O’Reilly Media (2019)