Java / Spark
이 포스트는 OSLab 연구 활동에서 작성한 개인 노트의 일부입니다. 공부 목적으로 작성된 내용이므로 많이 부족할 수 있습니다.
Java Virtual Machines
JVM (Java Virtual Machines) 이란 Java 코드를 바이트 코드로 변환하여 프로그램을 실행하게 하는 VM (Virtual Machine)의 일종이다. JVM 이란 하나의 명세서 (Specification)일 뿐이고, 이를 만족하는 환경을 제공하는 것을 JRE (Java Runtime Environment)라 한다. 이와 함께 Java 개발 환경을 제공하는 Toolkit을 JDK (Java Development Kit) 이라고 하며, 대표적으로 Oracle 사의 OpenJDK, JavaSE, JavaEE 등이 있다. 따라서 스펙만 만족한다면 Java를 가지고 있는 Oracle사 뿐만이 아닌 다른 환경 에서도 Java 프로그램의 구동이 가능하다. (IBM J9, Zulu, …)
JRE 만 있다면 Java로 쓰여진 프로그램을 실행하는 데에는 충분하다. 직접 Machine Code로 컴파일 해야 하는 C/C++과 같은 언어와는 다르게 Java로 쓰여진 프로그램은 JRE가 존재하는 환경이라면 어느 기기에서라도 실행이 가능하다.
- 이와 비슷한 개념으로 동작하는 언어-환경에는 Microsoft 사의 .Net (C#)이 있다.
Architecture
JVM의 구조는 아래의 그림과 같다. 아래는 JVM 명세를 만족한는 Oracle 사의 HotSpot JVM의 아키텍쳐를 나타내고 있다.
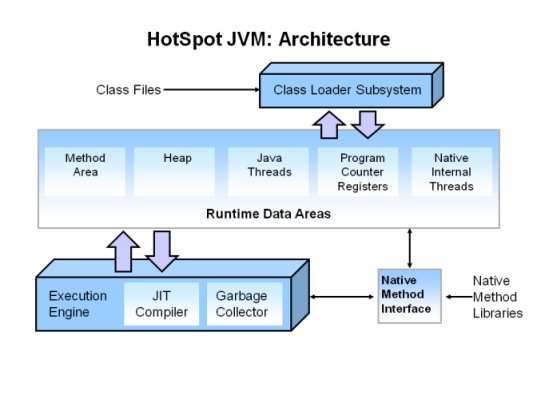
- 출처: https://www.oracle.com/webfolder/technetwork/Tutorials/obe/java/gc01/index.html
크게 세 부분으로 나눌 수 있다. Class Loader가 컴파일된 자바 바이트코드 (.class)를 런타임 데이터 영역Runtime Data Areas에 로드하고, Execution Engine이 자바 바이트코드를 실행한다. 그림에서 나타나는 Native Method Inteface (Java Native Interface, JNI)는 Java에서 지원하지 않는 네티이브 코드 실행을 위한 표준 인터페이스이다. 예를 들어 Architecture-specific한 asm/C/C++으로 작성된 프로그램, 또는 이러한 라이브러리 기능은 JVM 위에서 작동될 수 없기 때문에 직접 이 코드를 호출할 수 있도록 지원한다.
우선 관심있는 부분은 JVM의 메모리 모델에 관련된 부분이다. Runtime Data Areas는 프로그램이 실행되면서 할당받는 메모리 영역이다. 각 영역을 간단하게 정리하면 아래 표와 같이 나타낼 수 있다.
| Method Area | 클래스(class) 이름, 계층, 상수나 함수 이름, interface 등 Object에 대한 정보를 포함한다. 한 JVM 인스턴스에는 하나의 Method Area가 할당 되며 모든 쓰레드가 공유한다. JVM 인스턴스가 시작될 때 할당된다. |
|---|---|
| Heap | JVM의 Garbage Collector가 관여하는 영역. 변수 자원을 할당하고 해제하는 공간이다. 한 JVM 인스턴스에는 하나의 Heap이 할당 되며 쓰레드가 공유한다. 이 영역은 수동으로 관리 가능하다. |
| Java Threads | 각 쓰레드는 고유의 Stack을 갖는다. |
| PC Registers | 한 쓰레드의 현재 실행하고 있는 명령어의 주소를 저장한다. |
| Native Internal Threads | 각 쓰레드는 고유의 Native Stack을 갖고, 일반 스택과는 달리 JNI 지원을 위한 목적이다. |
Memory Allocation (Heaps)
Java 버전에 따라 메모리 모델과 명칭이 조금씩 상이하지만 여기에서는 Java 8 이후 업데이트 된 명칭을 사용하기로 한다. 메모리 구조는 아래의 그림과 같다.
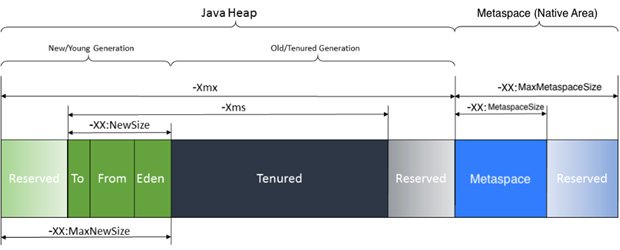
*출처: 링크
{kind=link}
Java Heap은 크게 두 가지 (또는 세 가지)의 종류로 나눌 수 있다.
- Heap
- Metaspace (Non-heap, Off-heap, Native Area)
Heap은 일반적인 C로 컴파일 된 프로그램과 같이 코드 실행 중 필요한 변수를 저장하기 위한 공간이다. 단, JVM은 Garbage Collector가 지속적으로 작동하면서 변수를 Tracking 하고, reference가 되지 않는 변수는 Heap으로부터 제거한다. 이 영역은 JVM 인스턴스가 시작되는 시점에 연속적으로 (Continuous) 할당을 받으며, 최소 및 최대 크기를 옵션을 통해 지정할 수 있다. 예를 들어, -Xms 옵션을 지정한다면 Heap 메모리를 최대 얼마까지 사용할 지 설정할 수 있다.
만일 큰 크기의 페이지 요청이 들어온다면 mmap 또는 shmat이 사용되기도 한다. 이 영역에서의 Garbage Collector는 운영체제로부터 메모리 할당 및 해제를 요청하고, 이후는 운영체제의 임무가 된다. Garbage Collector의 알고리즘으로는 기본적으로 Marking, Sweeping, Compacting 등이 있다. Java 버전에 따라 지원하는 알고리즘의 차이가 존재한다.
JVM은 필요에 따라 운영체제로부터 메모리를 할당 받는데, JVM이 시작(startup)될때 현재 운영 중인 어플리케이션에 최소 Heap (-xms)을 할당받는다. 만일 어플리케이션이 메모리를 더 필요로 한다면 최대로 설정한 (-Xmx) 크기 까지 메모리 블록을 할당받을 수 있다. JVM의 종류에 따라, 메모리 해제 방식은 다음과 같다.
- 어플리케이션이 명시적으로 메모리를 해제하면 JVM은 운영체제에게 메모리를 돌려준다.
- 어플리케이션이 명시적으로 메모리를 해제했으나 JVM 내부적으로 메모리를 Hold 한 상태를 유지한다. 이 경우에는 운영제체 입장에서 메모리를 사용 중인 것으로 인지한다.
Java 어플리케이션은 Java 코드가 작동하면서 필요로 하는 동적 메모리 외에도 어플리케이션 코드, JIT 코드, 내부 자료구조 등의 정보 (시스템 정보)를 저장할 공간이 필요하다. 또한 Heap 만으로는 만족할 수 없는 경우가 생기는데, 예를 들어 Garbage Collector의 오버헤드 없이 다량의 데이터를 캐싱해야 하는 경우, 복수의 JVM 사이에 Shared memory 영역이 필요한 경우, 또는 JVM이 크래쉬되는 경우를 방지하기 위해 memory persistent layer를 만드는 경우가 될 수 있다. Metaspace는 메모리 할당을 시도할 때 운영체제 malloc과 free의 메커니즘을 사용한다. 이때 무한정 커지는 경우 OutOfMemory 에러가 발생할 수 있기 때문에 이 영역 또한 옵션을 주어 크기를 지정하는 것이 가능하다. 그림에서 나타나는 것과 같이 -XX:MaxDirectMemorySize의 옵션을 사용할 수 있고 이 옵션을 지정하지 않는 경우에는 기본 옵션으로 -Xmx로 제한한 Heap 메모리만큼 Native Heap을 추가로 사용할 수 있다. 이 영역은 JVM이 관리할 수 있는 영역 밖에 존재하기 때문에 Standard C Library (libc)와 운영체제의 메모리 할당-해제 방식에 따라 그 방식이 결정된다.
이 Metaspace을 이용해 성능 향상을 하고 있는 어플리케이션들이 존재한다. 후술할 Spark가 이에 해당하며, 이외에도 많은 프로젝트 (Cassandra, Netty, 등)이 여기에 해당된다.
Running JVM in Kernel Space?
Reference의 Running a Java VM Inside an Operating System Kernel 에서는 Lightweight JVM 어플리케이션을 커널에서 동작하도록 시도하였다.
Reference
- JVM Internal
- STACK BASED VIRTUAL MACHINES - 1
- Active Control of Memory for Java Virtual Machines and Applications
- The native and Java heaps
- Understanding Java Memory Model and JVM Technology
- Tuning For Faster JVM Startup
- Java Memory Settings – JVM Heap Size
- Java Garbage Collection Basics
- [Java] Garbage Collection(가비지 컬렉션)의 개념 및 동작 원리 (1/2)
- JVM Native Memory Overview
- Running a Java VM Inside an Operating System Kernel
- A study of Java’s non-Java memory
- Understanding Memory Requirements for 32 and 64 Bit Systems
Spark
Spark (Apache Spark) 란 대용량 데이터 프로세싱을 위한 general purpose 분산 처리 시스템으로, 많은 부분이 Scala로 작성되오 있다. Spark 는 Java, Scala, Python 그리고 R으로 이루어진 API를 제공하고 있으며, 기본적으로 다양한 기능들을 내장하고 있다. 예를 들어 머신러닝 라이브러리인 MLlib, 그래프 프로세싱을 위한 GraphX가 있다. Spark의 구성 요소를 그림으로 나타내면 아래와 같다.
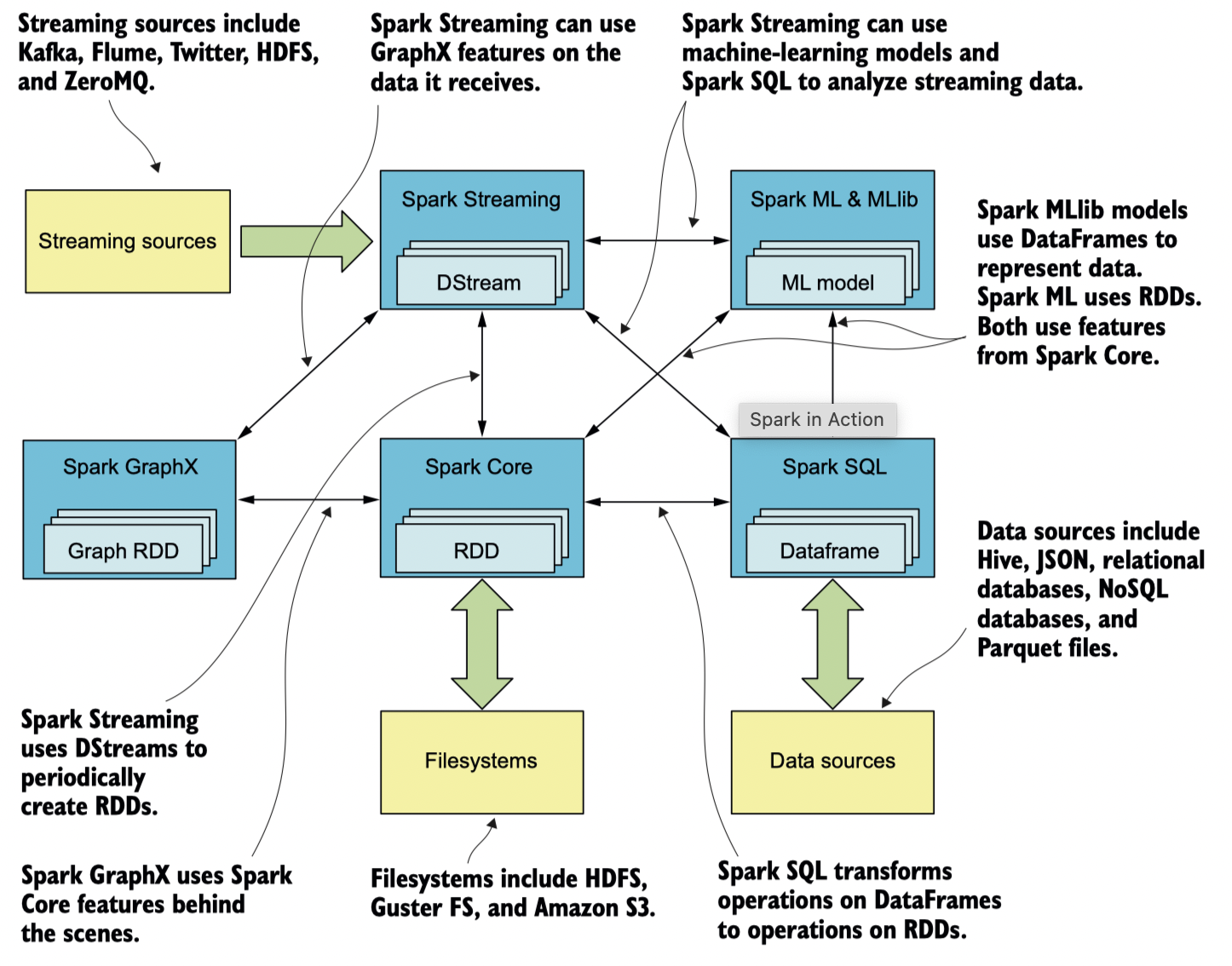
** 출처: Spark in Actions*
Spark는 기본적으로 Java Virtual Machine 만 설치되어 있다면 어떠한 운영체제에서도 실행이 가능하다. (참고로, Scala는 컴파일 시 Java Bytecode로 변환되므로 JVM 위에서 실행된다) 또한 분산처리 플랫폼이지만 한 대의 single machine 위에서 실행하는 것 또한 가능하다. Spark 3.2.1 기준으로 Java 8, Java 11 버전에서 실행 가능하며, Python API를 지원하는 PySpark의 경우 내부적으로 Py4J (Bridge between Python and Java)를 사용한다. Spark Runtime은 기본적으로 JVM 환경을 요구하기 때문에, 공식 문서에 작성되어 있는 Memory라는 단어는 일반적으로 JVM의 메모리를 뜻한다.
Py4J 는 파이썬 인터프리터에서 작동하는 프로그램이 JVM의 Java 오브젝트에 접근할 수 있도록 하는 라이브러리이다. 또 반대로 Java 프로그램이 Python 오브젝트로의 Call-back 또한 가능하게 한다.
Apache Spark와 Apache Hadoop의 큰 차이점은 in-memory execution model의 유무이다. Spark는 메모리를 최대한 활용하여 작업을 캐싱을 하고 in-memory computation을 지원하는 반면, Hadoop의 경우 HDFS (Hadoop Distributed File System) 이라는 파일시스템을 이용하여 데이터를 다루기 때문에 MapReduce 연산에 있어 약 100배의 성능 차가 존재한다. 또한 메모리를 활용하기 때문에 구조적으로 Hadoop 에서는 지원하지 않는 연산 또한 지원한다.
구성 요소(Component) 중 관심있는 부분을 간단히 설명하면 다음과 같다.
Spark Core:Spark가 운영됨에 있어 가장 기본적인 기능을 지원하는 component이다. 대규모 클러스터 환경에서 데이터셋을 다루는 기본 단위인RDD(Resilient Distributed Dataset)를 지원한다. 이와 함께 네트워킹, 보안, 스케줄링, data shuffling 등의 기능을 포함한다.Spark GraphX: 다양한 그래프 알고리즘 (page rank, connected components, shortest paths, SVD++, 등)을 지원한다. 그래프의 Vertex와 Edge는 그래프 알고리즘에 최적화된VertexRDD,EdgeRDD(RDD를 확장하여 만든 Type)으로 나타낸다.Spark MLlib: 머신 러닝 알고리즘(logistic regression, naïve Bayes classification, SVMs, decision trees, random forests, linear regression, 등)을 지원하는 라이브러리이다. 데이터는RDD로 표현이 가능하고,DataFrame이라는 타입으로도 표현이 가능하다. 공식 문서는 두 가지 타입을 기본으로 한 API를 모두 제공하고 있다.
Spark 의 클러스터 아키텍쳐는 아래의 그림과 같다. Spark 애플리케이션은 클러스터의 독립적인 프로세스 세트로 실행되는데, 주 프로그램(드라이버 프로그램)의 SparkContext 개체에 의해 조정된다.
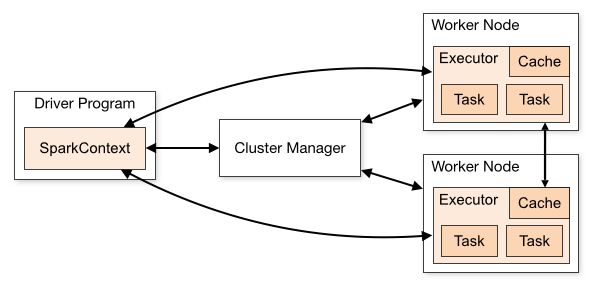
SparkContext 는 세 가지의 Cluster Manager에 연결되어 어플리케이션을 구동시킬 수 있는데, 기본으로 내장되어 있는 Standalone, Apache Mesos (Deprecated), Hadoop YARN, 그리고 Kubernetes가 있다. 그림에서 나타나는 Executor란 아래와 같이 설명하고 있다.
-
Executor
A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors.
RDD(Resilient Distributed Dataset)
Spark 가 지원하는 핵심적인 기능인 RDD (Resilient Distributed Dataset)는 병렬적으로 실행 가능한 (그리고 Fault-tolerant힌) 추상화된 데이터 단위라고 생각하면 된다. 아래의 그림을 보면 직관적인 이해가 가능하다.
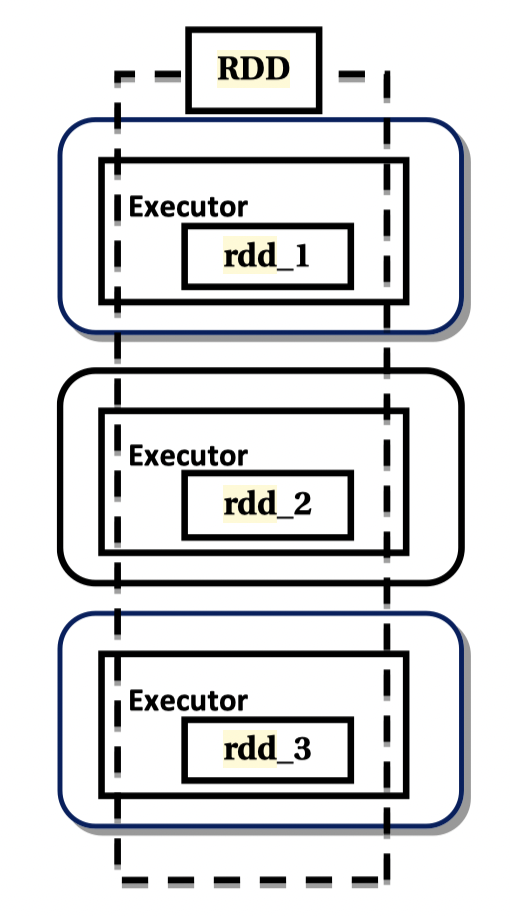
-
RDD
RDD is an immutable collection of distributed objects, elements partitioned across the nodes of clusters and operated on in parallel. ** 출처: Practical Apache Spark: Using the Scala API*
Spark는 RDD를 크게 세 가지 위치에 저장하는데, 주로 메모리(Java Heap)와 디스크 두 가지 영역을 사용하며, 옵션에 따라서 RDD의 저장 영역을 지정할 수 있다. 기본 설정은 메모리에 저장하도록 되어 있고, 옵션으로 디스크를 지정할 수 있다. 디스크를 지정하면 메모리에서 모지란 부분을 마치 swapping 하듯이 디스크에 데이타를 저장한다.
(Java) Heap Layout
앞서 언급했듯, Spark는 JVM 환경에서 작동하기 때문에 JVM 메모리 구조에 대한 이해가 필요하다. Spark의 JVM Heap은 크게 두 가지의 카테고리로 나눌 수 있다: Execution을 위한 영역, 그리고 Storage를 위한 영역이다. 여기서 Execution Memory이란 데이터 연산 처리에 필요한 영역이고, Storage Memory는 데이터 캐싱과 내부 데이터를 다른 클러스터로 이동시키기 위해 필요한 메모리이다. 이 두 영역은 동적으로 움직인다. 아래는 YARN Cluster Manager의 예시로 메모리 설정을 보여주고 있다.
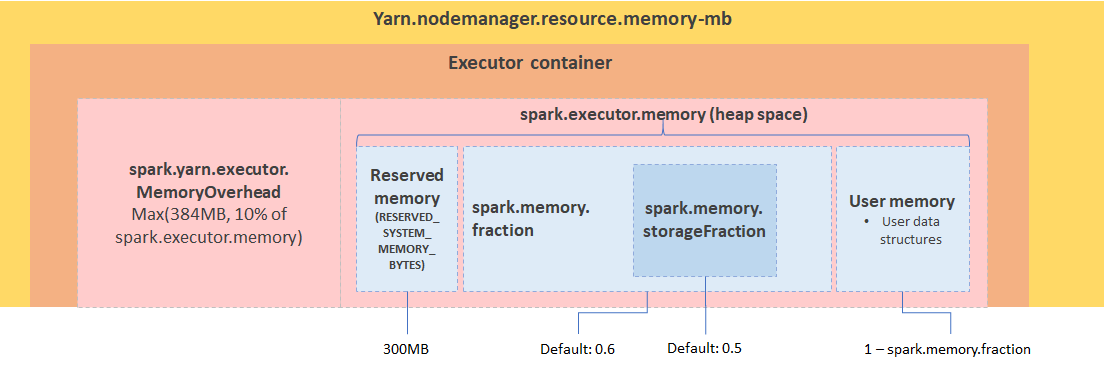
** 출처: https://miro.medium.com/max/1400/0AwwF6VFNLDu51avY.png**
Spark는 기본적으로 이 두 가지 영역을 공유하는 방식을 사용한다. 이를 Unified Region 이라 하고 UnifiedMemoryManager 에서 관리한다. 별다는 옵션을 지정하지 않았다면 Spark는 이 On-heap memory만 기본적으로 사용한다. 그림에서 나타나는 Reserved Memory는 시스템을 위한 (Spark 내부 오브젝트) 영역이고, User Memory는 RDD 연산을 위한 영역이다.
두 개의 Execution과 Storage 영역은 두 가지의 파라미터로 관리된다.
spark.memory.fraction: User Memory와 Unified Memory (Execution + Storage)를 구분하는 파라미터이다. 예를 들면 1GB의 메모리가 주어졌을 때 60%의spark.memory.fraction이라면 Unified Memory는 400MB가 할당된다.spark.memory.storageFraction: Unified Memory 내의 Execution Memory와 Storage Memory 비율을 결정하는 파라미터이다.
Off-Heap
Spark는 spark.memory.offHeap.enabled property 설정을 통해 JVM의 Off-heap 영역을 사용할 지의 여부를 지정할 수 있다. 기본적으로 이 property는 off으로 되어 있고, 만일 사용하겠다고 지정한다면 spark.memory.offHeap.size 또한 지정해 주어야 한다. 이 영역은 seralized 된 RDD 혹은 DataFrame을 보관하는데 사용될 수 있고, 혹은 기타 3rd party library 사용 목적을 위해 사용될 수 있다. JVM 에서의 Off-heap과 같이 Garbage Collector가 관여하지 않는 영역이기 때문에 Java 오브젝트의 GC로 인한 오버헤드를 피할 수 있다는 장점이 있다.
** Redis와 같은 솔루션 역시 JVM 밖의 네이티브 메모리 공간에 데이타를 저장하는 유사한 방식을 사용한다.*
Spark는 이러한 Off-Heap을 활용하여 발전된 메모리 관리와 성능 향상을 목적으로한 Umbrella Project인 Tungsten이 있었으나, 이는 Spark 1.4부터 기본적으로 적용되었다.
External Process Memory
Off-heap과 마찬가지로 JVM 외부에 존재하는 영역이다. 기본적으로 Spark는 JVM 환경 위에서 작동하므로, 다른 API인 R과 Python을 지원하기 위해 추가적인 SparkContext 오브젝트를 통해 통신하면서 SparkR과 PySpark을 동작시킨다. 순수 Java 또는 Scala로 작성된 어플리케이션에는 존재하지 않는 영역이다.
Reference
- Spark in Action
- Decoding Memory in Spark — Parameters that are often confused
- Spark Performance Optimization Analysis In Memory Management with Deploy Mode In Standalone Cluster Computing
- (Spark Summit) Deep Dive: Apache Spark Memory Management
- Tuning Spark
- Memory Management Approaches in Apache Spark: A Review
- Spark Configuration
- Spark Cluster Overview
- RDD Persistence