Yu Eee2020 Pah10
title: “[데이터구조] Merge Sort” date: 2020-04-18 09:00:00 header: overlay_image: /assets/static/header-yonsei.jpg show_overlay_excerpt: false categories:
- Electronic Engineering tags:
- Electronic Engineering
- Algorithm toc: true toc_sticky: true breadcrumbs: true
Merge Sort
Practice at Home 10 (Assignment)
Theory
Time Complexity
Time complexity is the computational complexity, which explains the amount of time taken to execute an algorithm. It is generally estimated by counting the number of operations executed, where the operations are supposed to take a constant time to perform.
There are several notations to represent the time complexity. Among them, Big O notation is widely used to express an algorithms’ complexity.
Merge Sort
Merge sort is one of the algorithms of sorting problem. It can be categorized to the one that uses divide and conquer method. The theoretical value of time complexity is given below.
\[O(n log n)\]Let us calculate the time complexity with the notation of Big O by the given file.
void mergeSort(int* arr, int l, int r) {
if (l < r) {
int m = (l + r - 1) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
merge(arr, l, m, r);
}
}
mergeSort function calls itself recursively by dividing the array into two groups. This method is called divide and conquer, which literally means that the algorithm divides the sample into groups and combines them after processing.
Dividing into groups are done 2^n times, where n represents half of the array size. Thus, when the recurrence is given as T(n), the equation below.
\[T(n)=2⋅T(n/2)+n\]The last term n is referred to the number of merge calls. The function merge will be later defined in the next section.
Unit Test Module
Namespace file_ctrl
To make a unit test code, let us make some simple structures of codes that can be reused in near future, for measuring time complexity. First, let us make a module for exporting test data in CSV file.
//
// file_ctrl namespace
// author: SukJoon Oh
namespace file_ctrl {
std::string record_file_name = "result";
std::ofstream record_file;
const bool openCsv(std::ofstream& file = record_file) {
if (!file.is_open())
file.open(record_file_name);
else return false;
return true;
}
const bool closeCsv(std::ofstream& file = record_file) {
if (file.is_open())
file.close();
else return false;
return true;
}
const bool writeCsv(const int data_size, const double time, std::ofstream& file = record_file) {
if (!file.is_open())
return false;
file << data_size << "," << time << "\n";
/* file << "\t";
file << time;
file << "\n";*/
return true;
}
}
The module is grouped into the namespace of file_ctrl. There are three simple functions, openCsv, writeCsv, and closeCsv.
openCsv function opens the file with the name stored in the global variable record_file_name. It receives the parameter of ofstream type for future extension, but the default argument is pre-set to the global variable record_file.
writeCsv function literally writes data to opened CSV file. Thus, the function openCsv must be called in advance. This module’s objective is to record the number of data n, and the elapsed time (second). Thus, this function records only two types of data, the sample sequence length, and the measured elapsed time.
closeCsv simply closes the opened file. This also receives the argument of ofstream reference type.
Namespace sort
For further extension, let us make a namespace named as sort. A variety sort methods will be declared in this namespace.
Since it requires sample data to test the time complexity, there must be a process of generating a sequence, or to specify, integer array. Thus, the function defined below, randomGen generates random integers and stores it to sample_arr location.
//
// sort namespace
// author: SukJoon Oh
namespace sort {
int* sample_arr = nullptr;
int* randomGen(int* &arr, const int size) {
if (arr == nullptr) {
srand(time(NULL));
arr = new int[size];
for (int idx = 0; idx < size; idx++)
arr[idx] = rand() / 100;
}
else {
}
return arr;
}
Now, let us make a function that performs unit test. Test method will be repeated over and over multiple times, since the measuring time complexity works in a way, that the program counts the time while executing sort functions.
The function defined as seqTestTimeComplexity, provides a tool for repeating the same process.
void seqTestTimeComplexity(const std::string& title,
std::function<void(int)> test_function = std::function<void(int)>(0)) {
file_ctrl::record_file_name = title + ".csv";
std::cout << "Time complexity test - " << title << std::endl;
file_ctrl::openCsv(); // open file
for (int sample_size = 1000; sample_size <= 1000000; sample_size += 50000) {
randomGen(sample_arr, sample_size); // generate test sample
auto start_t = std::chrono::steady_clock::now(); // clock tick
// test
test_function(sample_size);
auto end_t = std::chrono::steady_clock::now();
auto elapsed_seconds
= std::chrono::duration_cast<std::chrono::milliseconds>(end_t - start_t).count(); // clock end
delete[] sample_arr;
sample_arr = nullptr;
file_ctrl::writeCsv(sample_size, elapsed_seconds * 0.001);
std::cout << "Elapsed: " << elapsed_seconds * 0.001 << std::endl;
}
file_ctrl::closeCsv(); // close file
std::cout << "Time complexity end - " << title << std::endl;
}
For distinction, it receives a string type. This string type argument is also used to distinguish different files, which will be saved with the file name. The second parameter works as a kind of a function pointer. The std::function type is a wrapper for a function pointer, which is supported in the standard library. test_function variable holds a function’s name and executes it, as it is shown in the code, test_function(sample_size).
This function, seqTestTimeComplexity follows the process given below.
- Opens the file.
- Randomly generates integer to an array with different size. The array is dynamically allocated to the memory.
- Sets the time counter.
- Runs test_function.
- Turns off the time counter.
- Writes the result to the CSV file.
- Deallocate the array of sample data.
- Repeats several time with increased number of sample data.
Since this function will be provided to several sort algorithms for tests, it should be located right under the sort namespace.
Sort Algorithm
Selection Sort
Selection sort algorithm C++ application code is given in advance. The code is described below.
// given
namespace selection {
void swap(int *xp, int *yp) {
int temp = *xp;
*xp = *yp;
*yp = temp;
}
void selectionSort(int* A, int n) {
int i, j, min_idx;
for (i = 0; i < n - 1; i++) {
min_idx = i;
for (j = i + 1; j < n; j++)
if (A[j] < A[min_idx])
min_idx = j;
swap(&A[min_idx], &A[i]);
}
}
void unit_test(int size) {
selectionSort(sort::sample_arr, size);
};
}
Selection sort algorithm has time complexity of \(O(n^2)\). Thus, it is not as fast as the other sort algorithms.
As it is clearly shown, the function unit_test is for the selection sort algorithm unit test. Thus function will be given as an argument of std::function type, to seqTestTimeComplexity. It should be careful to make the unit test function to receive one int type argument and have void type as a return type. This is because the parameter std::function is actually, std::function<void(int)>, which means that the return type is void, and has one integer type parameter.
Merge Sort
Now, the mergeSort function was given in advance. Thus, merge function needs to be implemented.
Code below describes the sort::merge namespace.
namespace merge {
// merge sort algorithm
int* sorted_arr = nullptr;
// author: SukJoon Oh
void merge(int* arr, const int left, const int mid, const int right) {
int idx_l = left;
int idx_r = mid + 1;
int idx_s = left;
while (idx_l <= mid && idx_r <= right) {
if (arr[idx_l] <= arr[idx_r]) sorted_arr[idx_s++] = arr[idx_l++];
else sorted_arr[idx_s++] = arr[idx_r++];
}
// copy everything else
if (idx_l > mid)
for (int i = idx_r; i <= right; i++) sorted_arr[idx_s++] = arr[i];
else
for (int i = idx_l; i <= left; i++) sorted_arr[idx_s++] = arr[i];
for (int i = left; i <= right; i++)
arr[i] = sorted_arr[i];
}
// given by professor
void mergeSort(int* arr, int l, int r) {
if (l < r) {
int m = (l + r - 1) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
merge(arr, l, m, r);
}
}
// Test function
void unit_test(int size) {
sorted_arr = new int[size];
mergeSort(sort::sample_arr, 0, size - 1);
delete[] sorted_arr;
sorted_arr = nullptr;
}
}
It also has unit test function. This will perform perfectly same with the one that was shown in selection namespace.
The merge function ‘merges’ divided array. It first calculates indexes of two groups’ starting point. Then, it compares the values.
For merging process, merge sort algorithm requires additional memory space. Thus, it can be said that the algorithm earned time at the cost of memory space. The partially merged array will be stored in the additional array, and will be copied back to the original array. This process will be repeated until every groups are combined back together.
Result
The test procedure is defined in main function. The main function just need to simply call all the modules.
//
// app
// author: SukJoon Oh
int main() {
// pre-
namespace fc = file_ctrl;
namespace st = sort;
namespace mg = sort::merge;
namespace se = sort::selection;
std::cout << "Algorithm time complexity test" << std::endl;
st::seqTestTimeComplexity("merge_sort", mg::unit_test);
st::seqTestTimeComplexity("selection_sort", se::unit_test);
return 0;
}
As it is shown in the code, main function simply calls seqTestTimeComplexity by giving each unit test function as parameters. This way, it will perform each unit test.
This test was done in Windows 10 operating system, i5-9400F CPU, 32G of RAM. Of course, the time calculation is not exact, since there are various factors that affect the calculation. However, the objective here is to check the brief time complexity of two algorithm. Here is the result.
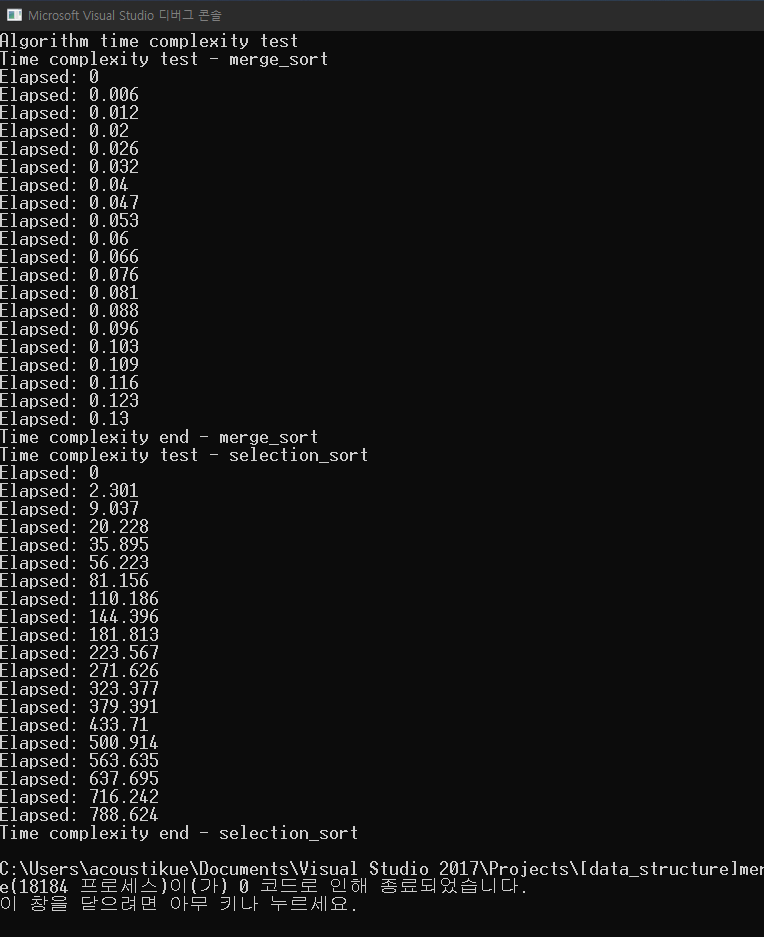
The measured unit is second. The files are exported so that it is easy to generate graph from the data.
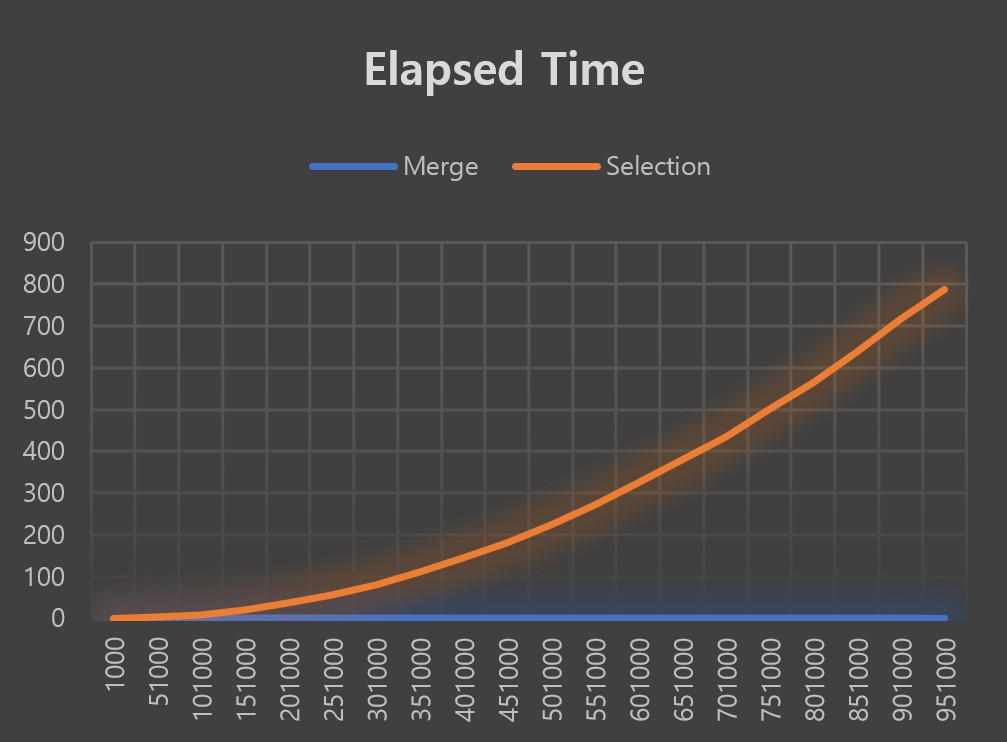
Discussion
It can be said that the selection sort algorithm’s time complexity follows \(O(n^2)\) as it is clearly shown in elapsed time graph. However, the merge sort algorithms is not clear since the measured time values are relatively too small to represent on the graph.
Although it was not able to visualize the result to the graph, it can be said that the algorithm has definitely great time complexity compared to the selection sort algorithm. Merge sort algorithm only took 0.13 seconds sorting 951000 data, while selection sort algorithm took 788.624 seconds, or nearly 13 minutes to sort 951000 data.
References
① Merge Sort - https://en.wikipedia.org/wiki/File:Merge_sort_algorithm_diagram.svg